Les expressions rationnelles dans SQL Server 2025
23 minutes à lire
Version 1 - Publiée le 16 décembre 2025 - Je vais enrichir l’article dans le futur avec des informations plus précises sur les regex.
Ça y est, nous avons enfin le support natif des expressions rationnelles dans SQL Server 2025, directement en T-SQL.
Ça fait vingt ans qu’on attendait ça. Cela élimine le recours aux assemblies CLR et simplifie de nombreux cas de recherche, comme la validation de contraintes check, l’extraction et la transformation de données complexes.
L’intégration native permet d’utiliser les regex dans des requêtes complexes, contraintes, index filtrés, et en interopérabilité avec d’autres fonctionnalités dans SQL Server.
Les expressions rationnelles (regex) sont un outil fondamental pour la manipulation avancée des chaînes de caractères, permettant de définir des motifs complexes pour la recherche, la validation et la transformation de données textuelles.
Les expressions rationnelles avant SQL Server 2025
Avant SQL Server 2025, la gestion des expressions rationnelles dans SQL Server était très limitée.
Les fonctions natives telles que LIKE, PATINDEX, ou STRING_SPLIT offrent des capacités basiques de recherche et de découpage de chaînes, mais elles sont loin de la puissance et de la flexibilité des regex modernes.
Par exemple, LIKE ne supporte qu’une syntaxe simplifiée avec des caractères jokers (%, _), et PATINDEX permet seulement de trouver la position d’un motif simple dans une chaîne.
Pour pallier ces limitations, les solutions alternatives les plus courantes sont les fonctions personnalisées via SQL CLR : il est possible d’intégrer des bibliothèques complètes de fonctions regex en CLR (.NET) sous formes d’assemblies, mais cela pose à l’évidence un problème de performances.
Fonctions regex dans SQL Server 2025
SQL Server 2025 propose cinq fonctions scalaires et deux fonctions tables (TVF, pour Table Valued Functions) pour manipuler les expressions rationnelles.
Les fonctions scalaires retournent une valeur par ligne :
REGEXP_LIKEteste si une chaîne correspond à un pattern (booléen),REGEXP_COUNTcompte les occurrences d’un motif,REGEXP_INSTRlocalise la position d’une correspondance,REGEXP_REPLACEeffectue des remplacements, etREGEXP_SUBSTRextrait des sous-chaînes.
Les fonctions TVF génèrent des ensembles de lignes :
REGEXP_MATCHESdétaille toutes les correspondances avec leurs positions, tandis queREGEXP_SPLIT_TO_TABLEdécoupe une chaîne en utilisant un pattern comme délimiteur.
Ces fonctions s’appuient sur la bibliothèque RE2 de Google, qui garantit un temps d’exécution linéaire par rapport à la taille de l’entrée, évitant les attaques par déni de service regex (ReDoS) possibles avec d’autres moteurs. Cette architecture assure une exécution sécurisée même avec des patterns complexes.
Les plateformes supportées incluent SQL Server 2025 (17.x), Azure SQL Database, Azure SQL Managed Instance (avec politique de mise à jour « SQL Server 2025 » ou « Always-up-to-date »), et SQL database in Microsoft Fabric.
| Fonction | Type | Description | Paramètres principaux | Retourne |
|---|---|---|---|---|
REGEXP_LIKE() | Scalaire | Valide si une chaîne correspond à un motif regex | Chaîne, motif regex, flags | 1 (vrai) ou 0 (faux) |
REGEXP_REPLACE() | Scalaire | Remplace les sous-chaînes correspondant au motif par une chaîne de remplacement | Chaîne, motif regex, remplacement, flags | Chaîne modifiée |
REGEXP_SUBSTR() | Scalaire | Extrait une sous-chaîne correspondant au motif regex | Chaîne, motif regex, position, occurrence | Sous-chaîne extraite |
REGEXP_COUNT() | Scalaire | Compte le nombre d’occurrences du motif dans la chaîne | Chaîne, motif regex | Nombre d’occurrences |
REGEXP_INSTR() | Scalaire | Localise la position d’une correspondance | Chaîne, motif regex, position, occurrence | Position (entier) |
REGEXP_MATCHES() | Table | Retourne une table avec les sous-chaînes correspondantes et leurs positions | Chaîne, motif regex | Table avec détails des correspondances |
REGEXP_SPLIT_TO_TABLE() | Table | Divise une chaîne en sous-chaînes selon un motif regex | Chaîne, motif regex | Table avec sous-chaînes et ordinal |
REGEXP_LIKE, REGEXP_MATCHES et REGEXP_SPLIT_TO_TABLE nécessitent le niveau de compatibilité 170 minimum pour fonctionner. Les autres fonctions regex sont disponibles à tous les niveaux de compatibilité dans SQL Server 2025. Pour vérifier ou modifier le niveau de compatibilité d’une base de données, utilisez les commandes suivantes :
-- Vérifier le niveau actuel dans la base courante
SELECT compatibility_level
FROM sys.databases
WHERE name = DB_NAME();
-- Modifier si nécessaire
ALTER DATABASE [MaBase]
SET COMPATIBILITY_LEVEL = 170;
Restrictions
- Les LOB (Large Objects)
varchar(max)etnvarchar(max)sont supportés avec une limite de 2 Mo pourREGEXP_LIKE,REGEXP_COUNTetREGEXP_INSTRuniquement. Les fonctionsREGEXP_REPLACE,REGEXP_SUBSTR,REGEXP_MATCHESetREGEXP_SPLIT_TO_TABLEne supportent pas les LOB. C’est une limitation due à la bibliothèque utilisée. - Trois restrictions limitent l’utilisation des regex dans certains contextes : les procédures stockées compilées nativement (In-Memory OLTP) ne peuvent pas exécuter de fonctions regex, les tables Memory-Optimized sont incompatibles, et les fonctions regex ne respectent pas les collations SQL pour les comparaisons linguistiques (comportement strictement basé sur Unicode).
- La longueur maximale d’un pattern est de 8 000 octets. Les répétitions avec quantificateurs explicites
{n},{n,m},{n,}sont limitées à 1 000 répétitions. Les fonctions ne supportent pas le lookahead ((?=...)) ni le lookbehind ((?<=...)) dans la syntaxe RE2. Cela vaut mieux cela dit, pour des raisons de performance. C’est l’absence de ce type de fonctionnalité qui rend RE2 rapide et moins gourmande en ressources.
Par exemple, la requête suivante échoue car elle utilise un lookbehind :
SELECT LastName,
CONCAT(UPPER(REGEXP_SUBSTR(LastName, '^\w')),
LOWER(REGEXP_SUBSTR(LastName, '(?<=^\w).+'))) AS [InitCap]
FROM Contact.Contact;
Le message d’erreur est :
Msg 19300, Level 16, State 1, Line 1
An invalid Pattern '(?<=^\w).+' was provided. Error 'invalid perl operator: (?<' occurred during evaluation of the Pattern.
La fonction REGEXP_LIKE valide les correspondances
REGEXP_LIKE teste si une chaîne correspond à un pattern. Sa syntaxe complète est :
REGEXP_LIKE ( string_expression, pattern_expression [ , flags ] )
Le paramètre string_expression accepte les types char, nchar, varchar ou nvarchar, incluant les types LOB jusqu’à 2 Mo. Le pattern_expression définit le motif regex avec une limite de 8 000 octets. Le paramètre optionnel flags (maximum 30 caractères) contrôle le comportement de la correspondance (par exemple insensibilité à la casse). La fonction retourne un booléen true ou false, comme un LIKE classique, pour être utilisé dans un prédicat.
REGEXP_LIKE nécessite le niveau de compatibilité 170 minimum pour fonctionner. Sans cette configuration, la requête échoue avec une erreur de syntaxe.
-- Changer le niveau de compatibilité : 170 (SQL Server 2025)
ALTER DATABASE PachadataTraining
SET COMPATIBILITY_LEVEL = 170;
GO
USE PachadataTraining
GO
-- Validation d'emails
SELECT
ContactId,
Email,
CASE
WHEN REGEXP_LIKE(Email, '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,6}$')
THEN 'Email valid'
ELSE 'Email invalid'
END AS ValidationEmail
FROM Contact.Contact
WHERE Email IS NOT NULL
ORDER BY ContactId;
-- Performances :
-- Avec regex : CPU time = 38 ms pour 10 319 lignes
-- Sans regex : CPU time = 8 ms pour 10 319 lignes
-- Clause WHERE avec REGEXP_LIKE : filtrer les noms contenant des caractères non alphabétiques
SELECT
ContactId,
FirstName,
LastName
FROM Contact.Contact
WHERE REGEXP_LIKE(LastName, '[^A-Za-zÀ-ÿ\s\-\'']');
L’utilisation dans une contrainte CHECK garantit l’intégrité des données à l’insertion :
ALTER TABLE Contact.Contact
ADD CONSTRAINT CK_Contact_Email_Valid
CHECK (REGEXP_LIKE(Email, '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}$'));
ALTER TABLE Contact.Contact
ADD CONSTRAINT CK_Contact_Telephone_Valid
CHECK (REGEXP_LIKE(Phone, '^\d{2}[\s.-]?\d{2}[\s.-]?\d{2}[\s.-]?\d{2}[\s.-]?\d{2}$'));
REGEXP_REPLACE pour transformer les chaînes
REGEXP_REPLACE offre des capacités de remplacement avancées avec support des groupes de capture. Sa syntaxe complète :
REGEXP_REPLACE ( string_expression, pattern_expression
[ , string_replacement [ , start [ , occurrence [ , flags ] ] ] ] )
Le paramètre string_replacement définit la chaîne de substitution (vide par défaut). Le paramètre start indique la position de départ (défaut: 1). Le paramètre occurrence spécifie quelle occurrence remplacer : 0 remplace toutes les occurrences, tandis qu’un entier positif cible la Nième occurrence uniquement.
Vous pouvez utiliser des back references (références arrière) : \1 à \9 référencent les groupes capturés, et & référence le pattern entier correspondant.
-- Formatage d'un numéro de téléphone avec groupes de capture
DECLARE @phone NVARCHAR(20) = '0612345678';
SELECT REGEXP_REPLACE(
@phone,
'(\d{2})(\d{2})(\d{2})(\d{2})(\d{2})',
'\1 \2 \3 \4 \5'
) AS FormattedPhone;
-- Résultat: 06 12 34 56 78
-- Masquage des 4 derniers chiffres d'une carte bancaire
SELECT REGEXP_REPLACE(NumeroCarte, '\d{4}$', '****') AS CarteMasquee
FROM Paiements;
-- Remplacement de la 2ème occurrence uniquement
SELECT REGEXP_REPLACE('A-B-C-D', '-', '/', 1, 2) AS Result;
-- Résultat: A-B/C-D
-- Suppression de tous les caractères non numériques
SELECT REGEXP_REPLACE(Telephone, '[^0-9]', '', 1, 0) AS TelephoneNettoye
FROM Contacts;
REGEXP_SUBSTR extrait des sous-chaînes
REGEXP_SUBSTR extrait la partie d’une chaîne correspondant au pattern spécifié. Elle fonctionne à n’importe quel niveau de compatibilité.
REGEXP_SUBSTR ( string_expression, pattern_expression
[ , start [ , occurrence [ , flags [ , group ] ] ] ] )
Le paramètre group permet d’extraire un groupe de capture spécifique : 0 retourne le match entier (défaut), tandis qu’un entier positif retourne le Nième groupe capturé.
-- Extraire le nom d'utilisateur et le domaine d'un email
SELECT
ContactId,
Email,
REGEXP_SUBSTR(Email, '^[^@]+') AS UserName,
REGEXP_SUBSTR(Email, '@(.+)$', 1, 1, '', 1) AS Domain
FROM Contact.Contact
WHERE Email IS NOT NULL;
-- Extraction du prénom et du nom séparément
DECLARE @Name varchar(50) = 'Isabelle D''Arco';
SELECT @Name,
REGEXP_SUBSTR(@Name, '\w+', 1, 1) AS FirstName,
REGEXP_SUBSTR(@Name, '[\w'']+', 1, 2) AS LastName;
-- Extraction d'un code postal français
DECLARE @address varchar(50) = '55 AVENUE MARECHAL FOCH 69006 LYON';
SELECT REGEXP_SUBSTR(@address, '\b\d{5}\b', 1, 1) AS CodePostal;
-- Premier mot commençant par une voyelle
SELECT
REGEXP_SUBSTR(m.text, '\b[aeiouàâäéèêëïîôùûü]\w*', 1, 1, 'i') AS Word,
m.text
FROM sys.messages m;
REGEXP_COUNT quantifie les occurrences
REGEXP_COUNT compte le nombre de correspondances d’un pattern dans une chaîne :
REGEXP_COUNT ( string_expression, pattern_expression [ , start [ , flags ] ] )
Cette fonction supporte les types LOB ([n]varchar(max)) jusqu’à 2 Mo et retourne un entier.
-- Compter les chiffres dans une chaîne
SELECT TOP 10
MontantHT,
REGEXP_COUNT(CAST(MontantHT as varchar(50)), '\d') AS NombreChiffres
-- pas de conversion implicite ...
FROM Enrollment.Invoice;
-- Compter les mots
SELECT verse,
REGEXP_COUNT(verse, '\b\w+\b') AS NbOfWords
FROM AI.Verses;
-- Compter les clés dans une chaîne JSON
SELECT TOP 10
JsonInfo,
REGEXP_COUNT(ClobInfo, '"[^"]+"\s*:') AS NombreCles
FROM Travel.Restaurant;
REGEXP_INSTR localise les correspondances
REGEXP_INSTR retourne la position d’une correspondance avec contrôle fin sur le résultat :
REGEXP_INSTR ( string_expression, pattern_expression
[ , start [ , occurrence [ , return_option [ , flags [ , group ] ] ] ] ] )
Le paramètre return_option détermine si la fonction retourne la position de début (0, défaut) ou de fin (1) de la correspondance.
-- Trouver la position du domaine dans l'email
SELECT
ContactId,
Email,
REGEXP_INSTR(Email, '[^@][A-Za-z0-9.-]+\.[A-Za-z]{2,}$') AS PositionDomain,
REGEXP_INSTR(Email, '@') AS PositionAt
FROM Contact.Contact
WHERE Email IS NOT NULL;
-- Position des espaces dans les noms complets
SELECT
ContactId,
CONCAT(FirstName, ' ', LastName) AS NomComplet,
REGEXP_INSTR(CONCAT(FirstName, ' ', LastName), '\s') AS FirstSpace,
REGEXP_INSTR(CONCAT(FirstName, ' ', LastName), '\s', 1, 2) AS SecondSpace
FROM Contact.Contact
WHERE FirstName IS NOT NULL AND LastName IS NOT NULL;
REGEXP_MATCHES (TVF) détaille toutes les correspondances
REGEXP_MATCHES retourne une table avec le détail de chaque correspondance :
REGEXP_MATCHES ( string_expression, pattern_expression [ , flags ] )
La table retournée contient les colonnes : match_id (bigint, séquence), start_position (int), end_position (int), match_value (même type que l’entrée), et substring_matches (JSON, détails des sous-groupes).
-- Extraire tous les hashtags d'un texte
SELECT * FROM REGEXP_MATCHES(
'Découvrez #SQLServer2025 et les #Regex pour #DataProcessing',
'#([A-Za-z0-9_]+)'
);
-- Retourne 3 lignes avec détails de chaque hashtag
-- Utilisation avec CROSS APPLY sur une table
SELECT E.EmployeID, M.match_id, M.match_value
FROM Employes E
CROSS APPLY REGEXP_MATCHES(E.Competences, '\w+') AS M;
REGEXP_SPLIT_TO_TABLE (TVF) découpe les chaînes
REGEXP_SPLIT_TO_TABLE divise une chaîne en lignes selon un pattern délimiteur :
REGEXP_SPLIT_TO_TABLE ( string_expression, pattern_expression [ , flags ] )
La table retournée contient value (sous-chaîne) et ordinal (position 1-based).
-- Découper une liste de compétences
SELECT * FROM REGEXP_SPLIT_TO_TABLE(
'SQL, Python, Java, JavaScript',
',\s*'
);
-- Retourne: SQL(1), Python(2), Java(3), JavaScript(4)
-- Découper un texte en mots
SELECT value, ordinal
FROM REGEXP_SPLIT_TO_TABLE('Le chat mange la souris', '\s+');
-- Utilisation avec une table
SELECT C.ClientID, S.value AS Tag, S.ordinal
FROM Clients C
CROSS APPLY REGEXP_SPLIT_TO_TABLE(C.Tags, ';\s*') AS S;
Ces deux fonctions TVF nécessitent le niveau de compatibilité 170 minimum.
La syntaxe RE2
Métacaractères et caractères spéciaux : Le moteur RE2 supporte les métacaractères standards : . correspond à tout caractère sauf newline, ^ ancre au début, $ ancre à la fin, \ échappe les caractères spéciaux, | représente l’alternance (ou logique), et les crochets [] définissent les classes de caractères.
Classes de caractères Perl : Les raccourcis Perl simplifient les patterns courants : \d équivaut à [0-9] (chiffres), \D à [^0-9] (non-chiffres), \s aux espaces blancs (espace, tab, newline), \S aux non-espaces, \w aux caractères de mot [0-9A-Za-z_], et \W aux non-caractères de mot.
Classes POSIX : Les classes POSIX offrent une alternative lisible aux raccourcis Perl : [[:alnum:]] pour les alphanumériques, [[:alpha:]] pour les alphabétiques, [[:digit:]] pour les chiffres, [[:lower:]] et [[:upper:]] pour les minuscules/majuscules, [[:space:]] pour les espaces, [[:word:]] pour les caractères de mot, et [[:xdigit:]] pour les hexadécimaux.
Quantificateurs : Les quantificateurs contrôlent les répétitions : * signifie zéro ou plus (greedy), + un ou plus, ? zéro ou un, {n} exactement n occurrences, {n,m} entre n et m, {n,} n ou plus. Les versions non-greedy (lazy) ajoutent un ? : *?, +?, ??, {n,m}?.
Les quantificateurs {n}, {n,m} et {n,} sont limités à 1 000 répétitions maximum. Les quantificateurs * et + n’ont pas cette restriction.
Groupes et références : Les parenthèses créent des groupes de capture numérotés : (pattern). Les groupes non-capturants (?:pattern) optimisent le traitement. Les groupes nommés (?P<nom>pattern) améliorent la lisibilité. Les références arrière \1 à \9 permettent de réutiliser les captures.
Ancres et limites de mots : Les ancres positionnent le match : ^ début de chaîne/ligne, $ fin de chaîne/ligne, \A début absolu de chaîne, \z fin absolue, \b limite de mot (word boundary), \B non-limite de mot.
Quatre flags contrôlent le comportement des correspondances
| Flag | Description | Valeur par défaut |
|---|---|---|
c | Correspondance sensible à la casse | Actif (défaut) |
i | Correspondance insensible à la casse | Inactif |
m | Mode multi-ligne : ^ et $ correspondent aux limites de ligne | Inactif |
s | Mode single-line : . correspond aussi aux retours à la ligne | Inactif |
Les flags se combinent dans une chaîne : 'im' active l’insensibilité à la casse et le mode multi-ligne. En cas de flags contradictoires (exemple : 'ic'), le dernier spécifié prévaut.
-- Recherche insensible à la casse
SELECT *
FROM Contact.Contact
WHERE REGEXP_LIKE(LastName, 'Simon', 'i');
-- Mode multi-ligne pour traiter des textes sur plusieurs lignes
SELECT REGEXP_REPLACE(Contenu, '^\s+', '', 1, 0, 'm') AS ContenuNettoye
FROM Articles;
-- Combinaison de flags
SELECT REGEXP_COUNT(TexteMultiLigne, '^ligne', 1, 'im') AS NombreLignes
FROM Documents;
Exemples concrets d’utilisation
Validation d’adresses email
-- Pattern email complet avec validation TLD
DECLARE @PatternEmail NVARCHAR(200) = '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}$';
-- Filtrer les emails valides
SELECT *
FROM Contact.Contact
WHERE REGEXP_LIKE(Email, @PatternEmail, 'i');
-- Rapport de qualité des données
SELECT
COUNT(*) AS TotalEmails,
SUM(CASE WHEN REGEXP_LIKE(Email, @PatternEmail, 'i') THEN 1 ELSE 0 END) AS EmailsValides,
SUM(CASE WHEN NOT REGEXP_LIKE(Email, @PatternEmail, 'i') THEN 1 ELSE 0 END) AS EmailsInvalides
FROM Contact.Contact;
Validation de numéros de téléphone français
-- Téléphone fixe ou mobile français (10 chiffres commençant par 0)
DECLARE @PatternTelFR NVARCHAR(100) = '^0[1-9](\s?|-?|\.?)\d{2}(\s?|-?|\.?)\d{2}(\s?|-?|\.?)\d{2}(\s?|-?|\.?)\d{2}$';
-- Validation
SELECT Phone,
CASE WHEN REGEXP_LIKE(Phone, @PatternTelFR)
THEN 'Valide' ELSE 'Invalide' END AS Statut
FROM Contact.Contact;
-- Normalisation (garder uniquement les chiffres)
UPDATE Contact.Contact
SET NormalizedPhone = REGEXP_REPLACE(Phone, '[^0-9]', '', 1, 0)
WHERE REGEXP_LIKE(Phone, '\d');
Validation de codes postaux et SIRET
-- Code postal français (5 chiffres, commence par 01-95 ou 97-98)
DECLARE @PatternCP NVARCHAR(50) = '^(0[1-9]|[1-8]\d|9[0-5]|97[1-6]|98[46-9])\d{3}$';
SELECT
c.Name,
c.ZipCode,
CASE WHEN REGEXP_LIKE(ZipCode, @PatternCP)
THEN 'Valide' ELSE 'Invalide' END AS StatutCP
FROM Reference.City c;
-- SIRET (14 chiffres)
DECLARE @PatternSIRET NVARCHAR(50) = '^\d{14}$';
SELECT * FROM Entreprises
WHERE REGEXP_LIKE(REGEXP_REPLACE(SIRET, '[\s.-]', '', 1, 0), @PatternSIRET);
Nettoyage et transformation de données
-- Supprimer les espaces multiples
UPDATE Documents
SET Contenu = REGEXP_REPLACE(Contenu, '\s+', ' ', 1, 0)
WHERE REGEXP_LIKE(Contenu, '\s{2,}');
-- Extraction de données structurées depuis du texte libre
SELECT TexteOriginal,
REGEXP_SUBSTR(TexteOriginal, '\b[A-Z]{2}\d{3}[A-Z]{2}\b') AS PlaqueFR,
REGEXP_SUBSTR(TexteOriginal, '\b\d{5}\b') AS CodePostal,
REGEXP_SUBSTR(TexteOriginal, '\b0[67]\d{8}\b') AS TelMobile
FROM Documents;
Masquage de données sensibles
-- Masquage de numéros de carte bancaire
SELECT
NumeroCarte,
REGEXP_REPLACE(
NumeroCarte,
'(\d{4})(\d{4})(\d{4})(\d{4})',
'XXXX-XXXX-XXXX-\4'
) AS CarteMasquee
FROM Paiements;
-- Masquage partiel des emails
SELECT Email,
REGEXP_REPLACE(
Email,
'^(.{2})(.*)(@.+)$',
'\1***\3'
) AS EmailMasque
FROM Contact.Contact;
Analyse des Performance
Effectuosn quelques analyses et comparaisons basiques de performances.
Requête simple de recherche avec LIKE sur la table Posts de la base StackOverflow2013.
La table Posts contient 17 142 169 lignes sur 38 Go de données.
--SET STATISTICS TIME, IO ON;
--ALTER DATABASE [StackOverflow2013] SET COMPATIBILITY_LEVEL = 170;
SELECT COUNT(*)
FROM Posts
WHERE Title LIKE '%SQL Server%';
GO
SELECT COUNT(*)
FROM Posts
WHERE REGEXP_LIKE(Title , 'SQL Server');
GO
SELECT COUNT(*)
FROM Posts
WHERE REGEXP_LIKE(Title , 'SQL Server', 'i');
Le LIKE simple consomme 32 secondes de CPU.
Table 'Posts'. Scan count 3, logical reads 4188571, physical reads 8, read-ahead reads 4168983.
SQL Server Execution Times:
CPU time = 32310 ms, elapsed time = 19485 ms.
Le REGEXP_LIKE consomme 483 secondes de CPU (8 minutes…).
Le temps d’exécution est de 4,3 minutes. Le degré de parallélisme est de 2…
Table 'Posts'. Scan count 3, logical reads 4186772, physical reads 2, read-ahead reads 4169796.
Table 'Worktable'. Scan count 0, logical reads 0.
SQL Server Execution Times:
CPU time = 483825 ms, elapsed time = 258479 ms.
Le REGEXP_LIKE avec l’option 'i' (insensible à la casse) consomme 999 secondes de CPU (16,6 minutes).
Le temps d’exécution est de 8,7 minutes. Le degré de parallélisme est toujours de 2. On voit bien le gain global du parallélisme sur une opération aussi lourde.
Table 'Posts'. Scan count 3, logical reads 4189766, physical reads 2, read-ahead reads 4172078.
Table 'Worktable'. Scan count 0, logical reads 0
SQL Server Execution Times:
CPU time = 999970 ms, elapsed time = 527492 ms.
Dans ce cas de recherche simple, REGEXP_LIKE est donc 15 fois plus lent que LIKE dans le cas d’une recherche stricte, et 31x plus lent pour une recherche insensible à la casse, qui correspond à la fonctionnalité apportée au LIKE par la collation CI de la colonne (SQL_Latin1_General_CP1_CI_AS).
Les requêtes impliquant des expressions rationnelles sont donc clairement « CPU bound ».
à noter que le type est NVARCHAR, donc en UTF-16.
Voyons si cet aspect est significatif dans la consommation CPU.
SELECT COUNT(*)
FROM Posts
WHERE REGEXP_LIKE(CAST(Title as varchar(250)) , 'SQL Server', 'i');
Pas vraiment… Le REGEXP_LIKE avec l’option ‘i’ sur une colonne convertie en VARCHAR consomme 1013 secondes de CPU (16,8 minutes).
Table 'Posts'. Scan count 3, logical reads 4190377, physical reads 9, read-ahead reads 4171470...
Table 'Worktable'. Scan count 0...
SQL Server Execution Times:
CPU time = 1013526 ms, elapsed time = 537002 ms.
Estimation de cardinalité
Un problème majeur avec les expressions rationnelles est l’estimation de cardinalité. L’estimateur de cardinalité de SQL Server n’est pas capable d’estimer correctement le nombre de lignes retournées par une expression rationnelle, car il n’a pas de modèle statistique pour cela. Comment pourriez-vous estimer le nombre de lignes correspondant à une expression rationnelle complexe ?
Le moteur d’estimation de cardinalité sait estimer la cardinalité sur l’opérateur LIKE en se basant sur les statistiques de chaînes, présentes depuis SQL Server 2005, qui donne une estimation sur les 80 premiers caractères d’un VARCHAR. Cela marche plutôt bien.
Dans notre exemple, nous cherchons les titres qui contiennent la chaîne ‘SQL Server’. La colonne Title est de type NVARCHAR(250), donc l’estimateur de cardinalité utilise les statistiques de chaînes pour un LIKE.
Voyons l’estimation de cardinalité pour le LIKE, sur l’opérateur IndexScan dans le plan d’exécution :
<RelOp AvgRowSize="261" EstimateCPU="9.42827" EstimateIO="3088.19"
EstimatedExecutionMode="Row" EstimateRows="100247" EstimatedRowsRead="17142200"
LogicalOp="Clustered Index Scan" Parallel="true" PhysicalOp="Clustered Index Scan"
EstimatedTotalSubtreeCost="3097.62" TableCardinality="17142200">
Dans les faits, la requête avec LIKE '%SQL Server%' retourne 43 467 lignes, ce qui est assez proche de l’estimation de 100 247 lignes du plan.
Voyons maintenant l’estimation de cardinalité pour le REGEXP_LIKE, toujours sur l’opérateur IndexScan dans le plan d’exécution :
<RelOp AvgRowSize="261" EstimateCPU="9.42827" EstimateIO="3088.19"
EstimatedExecutionMode="Batch" EstimateRows="1542800" EstimatedRowsRead="17142200"
LogicalOp="Clustered Index Scan" Parallel="true" PhysicalOp="Clustered Index Scan"
EstimatedTotalSubtreeCost="3097.62" TableCardinality="17142200">
Ici, l’estimateur de cardinalité estime 1 542 800 lignes retournées par le REGEXP_LIKE, ce qui est très loin des 43 467 lignes réellement retournées. L’erreur d’estimation est donc énorme, ce qui peut entraîner la non-utilisation d’un index par exemple, ou un memory grant excessif en cas de tri ou de hash.
Vous notez également que l’estimation de consommation CPU est identique entre les deux plans, ce qui est bien sûr totalement faux, comme on l’a vu sur la consommation CPU réelle.
L’estimation de cardinalité est identique pour l’expression rationnelle insensible à la casse.
En fait, l’estimateur de cardinalité semble utiliser un pourcentage fixe, ici 9% (1 542 800 / 17 142 200). Une vérification rapide avec un REGEXP_LIKE sur la table Comments montre le même pourcentage.
L’idée de base est sans doute de compter sur IQP (Intelligent Query Processing) pour ajuster dynamiquement l’estimation de cardinalité lors de l’exécution de la requête, et corriger les memory grants, mais ces fonctionnalités ne sont disponibles qu’en édition Enterprise, et c’est plutôt un pis-aller.
Options de requête pour l’estimation de cardinalité
Pour permettre au moins de corriger manuellement certaines grosses erreurs d’estimation, SQL Server propose deux options (hint) de requêtes.
SELECT COUNT(*)
FROM Posts
WHERE REGEXP_LIKE(Title , 'SQL Server', 'i')
OPTION (USE HINT ('ASSUME_FIXED_MIN_SELECTIVITY_FOR_REGEXP'));
<RelOp AvgRowSize="261" EstimateCPU="9.42827" EstimateIO="3088.19"
EstimatedExecutionMode="Row" EstimateRows="85710.8" EstimatedRowsRead="17142200"
LogicalOp="Clustered Index Scan" NodeId="5" Parallel="true" PhysicalOp="Clustered Index Scan"
EstimatedTotalSubtreeCost="3097.62" TableCardinality="17142200">
SELECT COUNT(*)
FROM Posts
WHERE REGEXP_LIKE(Title , 'SQL Server', 'i')
OPTION (USE HINT ('ASSUME_FIXED_MAX_SELECTIVITY_FOR_REGEXP'));
<RelOp AvgRowSize="261" EstimateCPU="9.42827" EstimateIO="3088.19"
EstimatedExecutionMode="Batch" EstimateRows="8571080" EstimatedRowsRead="17142200"
LogicalOp="Clustered Index Scan" NodeId="3" Parallel="true" PhysicalOp="Clustered Index Scan"
EstimatedTotalSubtreeCost="3097.62" TableCardinality="17142200">
Dans notre cas, l’option ASSUME_FIXED_MIN_SELECTIVITY_FOR_REGEXP donne une estimation de cardinalité de 85 710 lignes, ce qui correspond à environ 0,5 % de la table. L’option ASSUME_FIXED_MAX_SELECTIVITY_FOR_REGEXP donne une estimation de 8 571 080 lignes, donc 50 % de la table. Ces options de requêtes ne permettent pas de réaliser de grands progrès dans l’estimation de cardinalité, mais au moins elles permettent d’éviter les erreurs énormes.
Influence de la complexité de l’expression rationnelle sur les performances
Essayons de voir si la complexité de l’expression rationnelle produit des différences significatives de temps CPU.
ALTER DATABASE [PachadataTraining] SET COMPATIBILITY_LEVEL = 170;
GO
USE PachadataTraining;
GO
SET STATISTICS TIME ON;
GO
SELECT
ContactId,
Email,
CASE
WHEN REGEXP_LIKE(Email, '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,6}$')
THEN 'Email valid'
ELSE 'Email invalid'
END AS ValidationEmail
FROM Contact.Contact
WHERE Email IS NOT NULL;
-- simpler, less accurate
SELECT
ContactId,
Email,
CASE
WHEN REGEXP_LIKE(Email, '^[^\s@]+@[^\s@]+\.[^\s@]{2,}$')
THEN 'Email valid'
ELSE 'Email invalid'
END AS ValidationEmail
FROM Contact.Contact
WHERE Email IS NOT NULL;
SELECT
ContactId,
Email,
CASE
WHEN REGEXP_LIKE(Email, '^[A-Za-z0-9][A-Za-z0-9._%+-]{0,63}@[A-Za-z0-9][A-Za-z0-9.-]{0,62}\.[A-Za-z]{2,6}$')
THEN 'Email valid'
ELSE 'Email invalid'
END AS ValidationEmail
FROM Contact.Contact
WHERE Email IS NOT NULL;
Ici, nous testons trois expressions rationnelles de complexité croissante pour valider des adresses email dans la table Contact.Contact de la base PachadataTraining.
La première expression rationnelle est relativement simple et valide les adresses email de manière basique. Elle consomme environ 21 ms de CPU pour traiter 10 319 lignes.
La deuxième expression rationnelle est plus simple et moins précise, mais elle consomme environ 23 ms de CPU pour le même nombre de lignes, sans doute parce qu’elle utilise moins de classes de caractères et de quantificateurs précis.
La troisième expression rationnelle est plus complexe et valide les adresses email de manière plus rigoureuse. Elle consomme environ 27 ms de CPU pour traiter les mêmes 10 319 lignes.
La complexité de l’expression rationnelle a un impact direct mais relatif sur les performances.
SARGabilité des expressions rationnelles
Certaines expressions rationnelles dans SQL Server 2025 ont été présentées comme SARGables. En d’autres termes, elles peuvent potentiellement tirer parti des index pour améliorer les performances des requêtes, et être optimisées pas des recherches (seeks) de l’index plutôt que des scans.
Evidemment, cela ne serait possible que dans le cas où on cherche une correspondance au début d’une chaîne, par exemple avec une expression rationnelle comme ^abc, qui cherche les chaînes commençant par 'abc'.
Essayons cela :
ALTER DATABASE [PachadataTraining] SET COMPATIBILITY_LEVEL = 170;
GO
USE PachadataTraining;
GO
SELECT ContactId
FROM Contact.Contact
WHERE LastName LIKE 'Fera%';
SELECT ContactId
FROM Contact.Contact
WHERE REGEXP_LIKE(LastName , '^Fera', 'i')
OPTION (USE HINT ('ASSUME_FIXED_MIN_SELECTIVITY_FOR_REGEXP'));
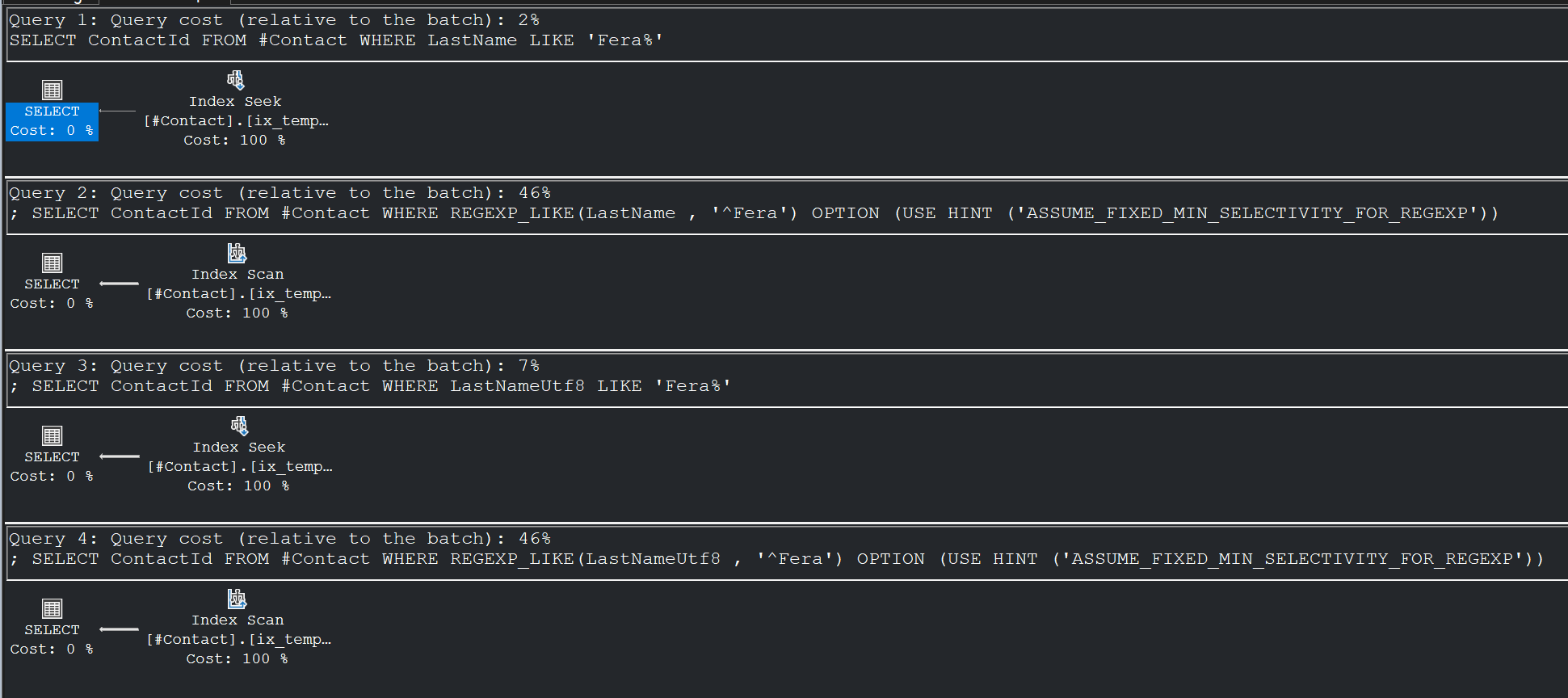
Ici, la première requête utilise un LIKE 'Fera%', qui est SARGable et peut utiliser un index sur la colonne LastName. Le plan d’exécution montre un Index Seek.
Pour l’essai avec REGEXP_LIKE('^Fera', 'i'), le plan d’exécution montre un Index Scan, ce qui indique que l’expression rationnelle n’a pas été considérée comme SARGable par l’optimiseur de requête, malgré la présence du caractère de début ^.
J’ai également essayé avec le flag multi-lignes 'm' et le flag single-ligne 's', mais cela n’a rien changé. La regex est restée non SARGable.
Pour augmenter les chances de SARGabilité, j’ai ajouté l’option de requête ASSUME_FIXED_MIN_SELECTIVITY_FOR_REGEXP, mais cela n’a pas aidé.
Je voulais avoir l’estimation la plus faible possible pour encourager l’optimiseur à utiliser un seek.
Ce n’était pas indispensable, car en affichant la colonne de l’index clustered dans le SELECT, je m’assure qu’il n’est pas nécessaire de faire un lookup. Mon index non clustered sur LastName couvre les besoins de la requête.
L’optimiseur n’a pas pu faire un seek malgré cela.
Je me suis demandé si cela pouvait être lié à la collation insensible à la casse de la colonne LastName (SQL_Latin1_General_CP1_CI_AS).
J’ai donc essayé avec une colonne en collation sensible à la casse. J’ai donc créé une table temporaire avec deux colonnes indexées, la première avec une collation binaire et la seconde avec une collation UTF-8 sensible à la casse, pour tout essayer.
ALTER DATABASE [PachadataTraining] SET COMPATIBILITY_LEVEL = 170;
GO
USE PachadataTraining;
GO
-- DROP TABLE #Contact
CREATE TABLE #Contact (
ContactId int PRIMARY KEY,
LastName varchar(50) COLLATE French_BIN2 index ix_temp_LastName,
LastNameUtf8 varchar(50) COLLATE Latin1_General_100_CS_AS_SC_UTF8
index ix_temp_LastNameUtf8
)
GO
INSERT INTO #Contact
SELECT ContactId, LastName, LastName
FROM Contact.Contact;
SELECT ContactId
FROM #Contact
WHERE LastName LIKE 'Fera%';
SELECT ContactId
FROM #Contact
WHERE REGEXP_LIKE(LastName , '^Fera')
OPTION (USE HINT ('ASSUME_FIXED_MIN_SELECTIVITY_FOR_REGEXP'));
SELECT ContactId
FROM #Contact
WHERE LastNameUtf8 LIKE 'Fera%';
SELECT ContactId
FROM #Contact
WHERE REGEXP_LIKE(LastNameUtf8 , '^Fera')
OPTION (USE HINT ('ASSUME_FIXED_MIN_SELECTIVITY_FOR_REGEXP'));
Dans aucun des cas, la fonction REGEXP_LIKE n’a permis d’obtenir un Index Seek, que ce soit avec une colonne en collation binaire ou en UTF-8 sensible à la casse.
Analyse de performance d’une requête simple
Prenons une requête simple qui utilise REGEXP_COUNT pour filtrer les titres de posts contenant exactement 5 mots. Voyons d’abord le code SQL :
SET STATISTICS TIME ON;
SELECT TOP 10 Title
FROM Posts
WHERE REGEXP_COUNT(Title, '\w+') = 5
ORDER BY Title;
Je la lance une première fois pour observer les statistiques de performance.
SQL Server Execution Times:
CPU time = 320221 ms, elapsed time = 82955 ms.
La requête consomme 320 secondes de CPU (plus de 5 minutes) pour traiter les titres des posts. Le temps d’exécution est de 83 secondes, le parallélisme défini au niveau du serveur est de 4.
J’ai 16 coeurs sur ma machine, je vais pousser le parallélisme à son maximum :
SELECT TOP 10 Title
FROM Posts
WHERE REGEXP_COUNT(Title, '\w+') = 5
ORDER BY Title
OPTION (MAXDOP 16);
SQL Server Execution Times:
CPU time = 672954 ms, elapsed time = 43590 ms
Le temps d’exécution diminue à 43 secondes, mais la consommation CPU augmente à 672 secondes (11 minutes). Le parallélisme permet de réduire le temps d’exécution, mais du quart. Cela s’explique : mon processeur est un AMD Ryzen 7 3700X avec 8 coeurs physiques et 16 threads logiques (SMT). SQL Server utilise les threads logiques pour le parallélisme, mais la charge CPU totale ne peut pas dépasser la capacité des coeurs physiques.
Terstons à 8 coeurs :
SELECT TOP 10 Title
FROM Posts
WHERE REGEXP_COUNT(Title, '\w+') = 5
ORDER BY Title
OPTION (MAXDOP 8);
SQL Server Execution Times:
CPU time = 431595 ms, elapsed time = 55577 ms.
Le temps d’exécution est de 55 secondes, avec une consommation CPU de 431 secondes (7 minutes). C’est un bon compromis entre temps d’exécution et consommation CPU.
On voit que le parallélisme aide vraiment à répartir la charge CPU importante des regex. C’est un comportement attendu pour des opérations CPU-bound, et légèrement différent de la plupart des requêtes opérationnelles que nous avons l’habitude d’exécuter, où nous essayons de ne pas trop paralléliser.
Stratégies d’optimisation pour réduire l’impact CPU
Pré-filtrer avec des prédicats rapides
La stratégie la plus efficace consiste à réduire le volume de données avant d’appliquer le regex :
-- Mauvais : regex sur toute la table
SELECT *
FROM Contact.Contact
WHERE REGEXP_LIKE(Email, '^[a-z]+\d+@gmail\.com$', 'i');
-- 28 ms de CPU
-- Bon : pré-filtrage avec LIKE puis regex
SELECT *
FROM Contact.Contact
WHERE Email LIKE '%@gmail.com' -- Filtre rapide d'abord
AND REGEXP_LIKE(Email, '^[a-z]+\d+@gmail\.com$', 'i'); -- Regex sur subset
-- 18 ms de CPU
Persister les résultats pour les validations fréquentes
Pour les colonnes fréquemment validées, calculer et stocker le résultat évite les recalculs :
-- Ajouter une colonne calculée persistée
ALTER TABLE Clients ADD EmailValide AS (
CAST(
CASE WHEN REGEXP_LIKE(Email, '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}$')
THEN 1 ELSE 0 END
AS BIT
)
) PERSISTED;
-- Index sur la colonne persistée
CREATE INDEX IX_Clients_EmailValide ON Clients(EmailValide);
Règles de conception des patterns
- Ancrer les patterns avec
^et$quand possible pour éviter les recherches partielles coûteuses - Utiliser les quantificateurs non-greedy (
*?,+?) pour réduire le backtracking - Éviter les patterns trop génériques comme
.*sans ancres - Préférer les classes de caractères explicites
[0-9]plutôt que\dpour la lisibilité
Mesurer l’impact CPU
Pour évaluer l’impact CPU des regex, activer les statistiques TIME avant d’exécuter la requête :
-- Activation des statistiques pour analyse
SET STATISTICS TIME ON;
SELECT * FROM GrandeTable
WHERE REGEXP_LIKE(Colonne, 'pattern');
SET STATISTICS TIME OFF;