Optimiser les procédures stockées
35 minutes à lire
Objectif
Il existe deux types de code SQL : la requête élaborée par le client et envoyée au serveur est appelée une requête ad-hoc, qui est souvent une requête saisie manuellement ou construite dynamiquement, et l’objet de code stocké, dont le plus courant est la procédure stockée. La procédure stockée offre de réels avantages de performances. Nous allons expliquer pourquoi, et vous donner les outils pour optimiser vos procédures.
La procédure stockée
La procédure stockée est un objet de code stocké sur le serveur, créé à
l’aide de la commande CREATE PROCEDURE.
Il est hors du domaine de ce livre de vous en présenter la syntaxe, nous allons simplement nous concentrer sur quelques éléments avancés qui vous permettront
d’optimiser leur utilisation.
Autant que possible, faites le choix des procédures stockées plutôt que
du code SQL généré du côté client (ce qu’on appelle des requêtes adhoc), même pour des requêtes très simples, comme un unique SELECT.
Les procédures stockées permettent d’encapsuler et de centraliser du code sur le serveur, qui n’aura besoin d’être modifié qu’à un seul endroit en cas de changement de logique ou de structure de données.
Elles permettent également de gérer la sécurité : grâce au principe de chaînage de propriétaire (ownership chaining), vous pouvez n’attribuer que les privilèges d’exécution sur une procédure, sans autoriser l’accès aux objets sous-jacents, ce qui vous permet de contrôler précisément les points d’entrée et de lecture de vos données. L’appel d’une procédure stockée est également plus concis que l’envoi d’un long code SQL, ce qui diminue le trafic réseau. Enfin, la procédure stockée est compilée une seule fois, et son plan d’exécution est conservé dans un cache en mémoire, ce qui évite des recalculs de plans d’exécution. Nous détaillerons cet aspect.
Messages done_in_proc
Par défaut, SQL server retourne un message au client après chaque exécution d’instruction SQL, indiquant le nombre de lignes affectées.
Vous le voyez dans l’onglet « messages » de SSMS, lorsque vous exécutez la moindre commande.
Ce message prend la forme : « (14 row(s) affected) » (pour une langue de session us_english).
Ce message est indépendant des jeux de résultats eux-mêmes, il est envoyé dans un paquet TDS à travers le réseau à chaque exécution d’une instruction, qu’elle soit dans un batch ou qu’elle fasse partie d’une procédure stockée.
Cela provoque des allers-retours réseau inutiles.
Dans la plupart des cas, ce message done_in_proc n’est pas utilisé par le client
TODO (la fonction SQLRowCount() en ODBC l’utilise, mais pas la propriété
RecordCount de l’objet ADODB.Recordset), vous pouvez donc obtenir un gain de performance sensible en désactivant l’envoi des tokens done_in_proc, surtout pendant l’exécution de procédures stockées complexes.
Pour cela, vous avez plusieurs solutions. La plus simple est de placer, en début de vos procédures stockées, l’instruction SET NOCOUNT ON, comme ceci :
CREATE PROCEDURE dbo.DoSomethingUseful
AS BEGIN
SET NOCOUNT ON;
...
Ce qui désactive le renvoi des messages done_in_proc pour le reste de la session.
Vous pouvez également désactiver globalement ces messages pour toutes les sessions, en modifiant le paramètre de serveur user options :
EXEC sp_configure 'user options', 512
RECONFIGURE
ou à l’aide du drapeau de trace 3640 à ajouter à la ligne de commande de démarrage du serveur SQL, dans les paramètres du service (propriété « Startup Parameters » du service Dans SQL Server Configuration Manager (voir section 7.5.2).
Malgré cela, c’est une bonne idée d’écrire systématiquement la commande SET NOCOUNT ON au début de toutes vos procédures stockées, car l’option a pu être remise à OFF dans la session (vous pouvez notamment configurer SSMS pour initialiser cette option à l’ouverture de session, voyez la fenêtre de propriétés de la requête, dans la page
« advanced »).
Enfin, vous pouvez tester quel est l’état de cette option de la façon suivante (exemple d’utilisation) :
IF @@OPTIONS & 512 = 512
PRINT 'SET NOCOUNT est à ON';
Maîtriser la compilation
Un avantage important de la procédure stockée, est la réutilisation de son plan d’exécution. Nous allons détailler ce mécanisme. Ci-dessous, nous ne parlerons que de procédures, mais gardez à l’esprit que le mécanisme est le même pour les fonctions utilisateur (UDF) et pour les déclencheurs, qui sont précompilés de la même manière.
Lorsque la procédure est créée via une instruction CREATE PROCEDURE, son code source est stocké dans une table système de métadonnées de la base courante.
Vous pouvez retrouver ce code grâce à la vue système sys.sql_modules :
SELECT definition
FROM sys.sql_modules
WHERE object_id = OBJECT_ID('dbo.uspGetBillOfMaterials')
Cette requête retourne la définition de la procédure nommée dbo.uspGetBillOfMaterials.
La vue sys.sql_modules interroge des tables systèmes qui ne peuvent plus être requêtées directement depuis SQL Server 2005.
Si vous êtes curieux de savoir comment ces tables systèmes s’appellent, vous pouvez retrouver la définition de cette vue (comme de tous les objets système) à l’aide d’un de ces commandes :
SELECT OBJECT_DEFINITION(OBJECT_ID('sys.sql_modules'))
-- ou
SELECT definition FROM sys.system_sql_modules
WHERE Object_Id = OBJECT_ID('sys.sql_modules')
Ce stockage n’implique en rien une compilation, ou une optimisation.
Il faut distinguer en SQL Server la phase de compilation, à proprement dit la vérification des privilèges de l’utilisateur et de l’existence des objets, de l’optimisation.
L’optimisation est la génération d’un plan d’exécution pour le code SQL.
Lorsque la procédure est créée, rien de tout cela n’est fait, même pas la vérification de l’existence des objets : on peut créer une procédure qui référence des tables qui n’existent pas, par les vertus de la fonctionnalité de « résolution de
nom différée » (Deferred Name Resolution) TODO.
Cette résolution différée ne s’applique qu’aux tables (et aux vues, qui sont syntaxiquement et conceptuellement identiques aux tables).
Tout autre objet référencé, comme une procédure stockée appelée par un EXECUTE, ou une colonne d’une table, doivent exister.
Ainsi, à la création de la procédure, on peut dire que seule une vérification syntaxique du code SQL est effectuée.
La vérification de l’existence des tables, comme l’optimisation, ne seront réalisées que lors de la première exécution de la procédure stockée.
Par « première exécution », nous entendons première exécution depuis le démarrage de l’instance SQL.
Le plan d’exécution généré pour la procédure lors de sa première exécution sera stocké en mémoire vive, dans ce qu’on appelle le cache de plans, ou plus anciennement cache de procédures.
Lors des exécutions ultérieures de la procédure, ce plan sera utilisé, ce qui économise l’étape d’optimisation.
Le plan reste dans le cache jusqu’au redémarrage du service.
Il est également possible que, à cause d’une pression sur la mémoire, le cache se nettoie.
Il ne contient au maximum que deux versions d’un plan pour une procédure : la version « sérielle » (monoprocesseur) et éventuellement la version parallélisée.
De plus, ce plan est stocké sans information d’utilisateur, nous verrons dans la partie 9.1.2, ce que cela implique.
Le cache de procédure peut être examiné à l’aide d’une vue de gestion dynamique : sys.dm_exec_cached_plans.
Alliée aux fonctions tables sys.dm_exec_sql_text() et sys.dm_exec_query_plan(), elle vous permet d’observer en détail ce qui réside dans le cache :
SELECT
cp.usecounts,
cp.size_in_bytes,
st.text,
DB_NAME(st.dbid) as db,
OBJECT_SCHEMA_NAME(st.objectid, st.dbid) + '.'
+ OBJECT_NAME(st.objectid, st.dbid) as object,
qp.query_plan,
cp.cacheobjtype,
cp.objtype
FROM sys.dm_exec_cached_plans cp
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st
CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) qp;
En exécutant cette requête, vous constaterez que la colonne cp.objtype contient différents types de requêtes, et pas seulement des procédures stockées.
Nous reviendrons sur la capacité de SQL Server à cacher d’autres plan d’exécution plus loin.
Vous pouvez constater en observant cette requête que la vue sys.dm_exec_cached_plans retourne les colonnes usecounts et size_in_bytes, fort utiles pour juger de la taille et de l’utilité du cache.
Bien entendu, usercounts indique le nombre de réutilisation du plan d’exécution, et size_in_bytes sa taille en mémoire.
Le cache d’une procédure complexe peut prendre plusieurs mégaoctets.
La taille indiquée ne dépend d’ailleurs pas seulement de la complexité du plan d’exécution, elle varie aussi selon le nombre d’exécutions simultanées de la procédure ou du batch, car, comme nous le verrons, des plans en rapport avec le contexte d’exécution sont générés à l’exécution à partir de ce plan compilé, et eux-mêmes cachés.
On aura compris une chose : un serveur SQL fortement sollicité, et qui exécute des requêtes complexes, gagnera fortement à avoir le plus de mémoire de travail possible.
Dès que le plan d’exécution de la procédure est en cache, il sera réutilisé à chaque appel ultérieur, économisant ainsi le calcul coûteux du plan d’exécution. Vous pouvez facilement observer les différences de temps d’exécution entre le premier appel d’une procédure et les suivantes avec le profiler ou les évènements étendus, et notamment sur la valeur en temps CPU, qui inclut le temps de compilation.
Normalement, la procédure va rester dans le cache. En revanche, comme la mémoire est limitée, il peut arriver qu’une pression sur la mémoire oblige SQL Server à nettoyer le cache[^32], pour faire de la place pour la mémoire de travail. Dans ce cas, SQL Server va tout de même s’efforcer de conserver les plans les plus coûteux à recréer.
Vous pouvez vous faire une idée du coût d’un plan à l’aide des colonnes original_cost et current_cost de sys.dm_os_memory_cache_entries.
Exemple de requête :
SELECT
DB_NAME(st.dbid) as db,
OBJECT_SCHEMA_NAME(st.objectid, st.dbid) + '.'
+ OBJECT_NAME(st.objectid, st.dbid) as object,
cp.objtype, cp.usecounts, cp.size_in_bytes,
ce.disk_ios_count, ce.context_switches_count,
ce.pages_allocated_count, ce.original_cost, ce.current_cost
FROM sys.dm_exec_cached_plans cp
JOIN sys.dm_os_memory_cache_entries ce
ON cp.memory_object_address = ce.memory_object_address
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st
Pression sur le cache de plans
Un verrou de compilation est posé sur une procédure lors de sa compilation. Il ne peut y avoir qu’une seule compilation de la même procédure à la fois, ce qui signifie que si la compilation est longue, tous les utilisateurs seront en attente de la fin de la compilation.
Pour éviter ce type de problèmes, n’écrivez pas de procédures trop longues ou complexes, modularisez au besoin, et assurez-vous de disposer de suffisamment de mémoire de travail.
Si vous souhaitez vider le cache, par exemple pour réaliser des tests consistants de performances, vous disposez de la commande DBCC FREEPROCCACHE, qui vide entièrement le cache de plans.
Elle est en général utilisée conjointement avec DBCC DROPCLEANBUFFERS, pour obtenir un état de la mémoire proche d’un démarrage de l’instance SQL.
CHECKPOINT
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE
Il vaut mieux bien entendu éviter de lancer ces commandes sur un serveur de production, qui verrait immédiatement ses performances se dégrader jusqu’à ce que le cache soit de nouveau rempli.
Deux autres commandes DBCC, moins connue permettent de vider le cache : pour les plans qui s’appliquent à une base de données spécifique : DBCC FLUSHPROCINDB (DBID) :
SELECT DB_ID('AdventureWorks')
DBCC FLUSHPROCINDB (5)
Note
Une version plus moderne de cette commande existe maintenant, qui évite l’appel auce vieilles commandesDBCC:ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE CACHE
TODO
Pour vider plus généralement les caches de SQL Server : DBCC FREESYSTEMCACHE('ALL').
Plus d’informations sur cette entrées de blog : http://sqlblog.com/blogs/kalen_delaney/archive/2007/09/29/geek-city-clearing-a-single-plan-from-cache.aspx
Il est également à noter que le cache se vide intégralement lors de quelques opérations, qu’il faut donc éviter d’exécuter inutilement sur un serveur de production :
détachement d’une base de données (
sp_detach_db) ;utilisation de la commande
RECONFIGUREpour appliquer les changements d’une option de serveur ;lorsqu’une vue est créée avec
CHECK OPTION, toutes les entrées du cache qui référencent la base de données dans laquelle se trouve la vue, sont vidées ;
Si vous êtes confrontés à des nettoyages de cache intempestifs, consultez le journal d’erreur (ERRORLOG) de SQL Server.
Un message d’information y est enregistré lorsque le cache se vide (aussi à l’issue d’un DBCC FREEPROCACHE).
Vous pouvez également tracer l’événement SQL Trace Errors and Warnings : ErrorLog.
L’événement Security Audit : Audit DBCC Event se déclenche également à l’exécution de toute commande DBCC.
Paramètres typiques
Sur quelle base le plan d’une procédure est-il calculé ? Lorsque nous passons des paramètres, leurs valeurs peuvent différer et générer des plans d’exécution différents. Qu’en est-il alors du comportement de la procédure stockée ? Malheureusement, il n’y a en ce domaine pas de miracle : toutes les instructions de la procédure sont optimisées en tenant compte des valeurs de paramètres envoyées. Le premier appel impose donc la qualité du plan d’exécution. Si la valeur des paramètres est « typique », le plan sera de bonne qualité. En revanche, si des paramètres « extrêmes » sont passés, cela peut produire de mauvaises performances lors des appels ultérieurs.
Prenons l’exemple de ces deux requêtes :
--créons un index pour aider la recherche
CREATE INDEX [nix$Person_Contact$LastName]
ON [Person].[Contact] (LastName)
GO
-- 2 lignes à retourner
SELECT FirstName, LastName, EmailAddress
FROM Person.Contact
WHERE LastName LIKE 'Ackerman'
-- 911 lignes à retourner
SELECT FirstName, LastName, EmailAddress
FROM Person.Contact
WHERE LastName LIKE 'A%'
À l’évidence, le plan d’exécution sera différent : la sélectivité de l’index est excellente pour répondre à la première requête, et SQL Server choisira un seek ; En revanche, la deuxième requête sera résolue par un scan, probablement moins coûteux.
Vous comprenez déjà le problème : si nous créons une procédure stockée de ce type :
CREATE PROCEDURE Person.GetContactByLastName
@LastNameStart nvarchar(50)
AS BEGIN
SET NOCOUNT ON;
SELECT FirstName, LastName, EmailAddress
FROM Person.Contact
WHERE LastName LIKE @LastNameStart;
END
Nous pouvons aisément vérifier que le plan d’exécution mis en cache dépend du paramètre envoyé lors du premier appel de la procédure.
Exécutons une première fois la procédure, et examinons le plan en cache :
EXEC Person.GetContactByLastName 'A%'
GO
SELECT cp.size_in_bytes, qp.query_plan
FROM sys.dm_exec_cached_plans cp
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st
CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) qp
WHERE st.dbid = DB_ID('Adventureworks') AND
st.objectid = OBJECT_ID('Adventureworks.Person.GetContactByLastName')
Dans le plan XML, nous trouvons l’opérateur de scan d’index clustered, donc de table :
<RelOp NodeId="0" PhysicalOp="Clustered Index Scan"
LogicalOp="Clustered Index Scan" EstimateRows="911.466"
EstimateIO="0.540903" EstimateCPU="0.0221273" AvgRowSize="126"
EstimatedTotalSubtreeCost="0.56303" Parallel="0"
EstimateRebinds="0" EstimateRewinds="0"\>
Si nous appelons la procédure avec le paramètre 'Ackerman', et que nous examinons le plan d’exécution dans SSMS, nous constatons que l’opérateur est toujours un scan : le plan a été réutilisé, alors qu’il n’est de loin pas, dans ce cas, par rapport au paramètre envoyé, le plus efficace.
La procédure est compilée en utilisant une fonctionnalité appelée parameter sniffing (littéralement « flairage de paramètre ») : le moteur d’optimisation détecte la valeur du paramètre passé. Le plan sera donc calculé selon le paramètre envoyé lors du premier appel de la procédure. Si c’est ‘Ackerman’, la procédure fera toujours un seek, si c’est ‘A%’, elle scannera toujours la table. Le parameter sniffing est une bonne chose lorsque le premier appel est passé avec des paramètres représentatifs des futurs appels de la procédure. En revanche, c’est une mauvaise chose lorsque le premier appel est un cas particulier. Nous allons en faire la démonstration, ce qui nous permettra de démontrer une autre particularité du parameter sniffing :
-- procédure avec utilisation directe du paramètre
CREATE PROCEDURE dbo.GetContactsParameter
@LastName nvarchar(50) = NULL
AS BEGIN
SET NOCOUNT ON
SELECT FirstName, LastName FROM Person.Contact
WHERE LastName LIKE @LastName;
END
GO
-- procédure avec variable locale
CREATE PROCEDURE dbo.GetContactsLocalVariable
@LastName nvarchar(50) = NULL
AS BEGIN
SET NOCOUNT ON
DECLARE @MyLastName nvarchar(50)
SET @MyLastName = @LastName
SELECT FirstName, LastName FROM Person.Contact
WHERE LastName LIKE @MyLastName;
END
GO
-- utilisation
EXEC dbo.GetContactsParameter @LastName = 'Abercrombie'
GO
EXEC dbo.GetContactsLocalVariable @LastName = 'Abercrombie'
GO
EXEC dbo.GetContactsParameter @LastName = '%'
GO
EXEC dbo.GetContactsLocalVariable @LastName = '%'
GO
Avant d’expliquer la raison pour laquelle nous avons créé deux procédures, observons les résultats de l’exécution, en figure 9.1.
Nous y voyons les statistiques d’exécution des quatre appels de procédure, ainsi que le plan d’exécution généré du premier appel.
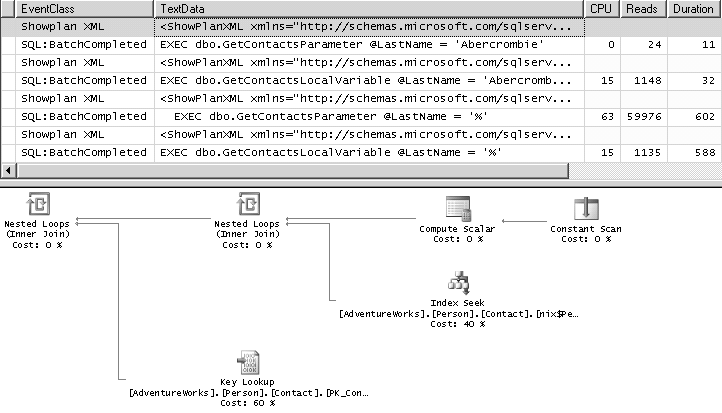
Nous avons passé d’abord le nom 'Abercrombie', la compilation de la procédure a donc produit un plan basé sur un seek d’index.
Ce plan sera réutilisé tout au long des exécutions futures de la procédure, ce que nous voyons plus loin : un appel avec le paramètre '%' génère près de 60 000 reads : le moteur de stockage a été forcé de parcourir près de 20 000 l’index, pour trouver l’emplacement de chaque ligne de la table.
Et qu’en est-il de la deuxième procédure ? Nous sommes passé par une variable locale, à laquelle nous avons affecté la valeur du paramètre, et nous avons ensuite utilisé cette variable locale comme opérande de l’expression de filtre.
Ce que nous voulions montrer, c’est que cette syntaxe ne permet pas le parameter sniffing. Dans ce cas, le plan d’exécution généré prend en compte une distribution moyenne des valeurs dans la colonne, et non pas la valeur actuellement passée à la requête, ceci simplement parce que cette valeur n’est pas connue lors de l’optimisation.
Dans notre cas, la distribution moyenne incite SQL Server à choisir un scan.
Lors du premier appel, cette stratégie est plus coûteuse que le seek.
En revanche, lors du second appel, le résultat est bien plus cohérent en terme de temps CPU et de reads.
Dans le deuxième cas, le scan est la bonne stratégie.
Il est donc important que vous preniez ce comportement en compte lorsque vous créez des procédures stockées. Souvent, les paramètres sont assez consistants, et vous n’avez pas à vous soucier du premier plan d’exécution généré, mais dans certains cas, vous devez gérer ces différences, soit en écrivant vos procédures stockées différemment (en les modularisant, par exemple), soit en les forçant à se recompiler.
Forcer la recompilation
Que faire pour résoudre le problème des appels de procédures stockées avec des paramètres s’appliquant à des colonnes dont la distribution est très variable ? Une solution est de provoquer, manuellement, la recompilation.
Cela peut être fait de plusieurs façons.
Premièrement, avec l’option WITH RECOMPILE peut être indiquée dans le corps de la
procédure stockée, ou indépendamment, à chaque appel :
ALTER PROCEDURE Person.GetContactByLastName
@LastNameStart nvarchar(50)
WITH RECOMPILE
AS BEGIN ...
-- ou :
EXEC Person.GetContactByLastName 'Ackerman' WITH RECOMPILE
La première méthode, qui force la recompilation à chaque appel, est utile pour une procédure où les valeurs de paramètres sont très différentes chaque fois, la seconde, pour forcer la recompilation dans des cas particuliers.
Si votre procédure n’est appelée qu’avec des paramètres atypiques, préférez la première solution. La seconde est d’une utilité particulière : un EXEC …
La recompilation est une opération coûteuse, c’est pourquoi il vaut mieux limiter l’usage du WITH RECOMPILE à des procédures de petite taille, qui en ont vraiment besoin, c’est-à-dire où le coût de la recompilation est moindre que celui de l’exécution avec un plan inefficace.
Pour les procédures qui comportent de multiples instructions, vous pouvez sélectionner une recompilation instruction par instruction, à l’aide de l’indicateur de requête OPTION (RECOMPILE). Par exemple :
CREATE PROCEDURE dbo.GetContactsParameter
@LastName nvarchar(50) = NULL
AS BEGIN
SET NOCOUNT ON;
SELECT FirstName, LastName
FROM Person.Contact
WHERE LastName LIKE @LastName
OPTION (RECOMPILE);
END
Une meilleure solution est de forcer, toujours par indicateur de requête, sur quelle valeur l’optimiseur doit se baser :
SELECT FirstName, LastName
FROM Person.Contact
WHERE LastName LIKE @LastName
OPTION (OPTIMIZE FOR (@LastName = '%'));
Le désagrément de cette approche étant évidemment de coder en dur une valeur de la colonne, qui peut évoluer à travers le temps, ou disparaître.
SQL Server 2008
en SQL Server 2008, l’indicateur OPTIMIZE FOR est complété de la façon suivante :
OPTION (OPTIMIZE FOR (@variable = UNKNOWN)), ouOPTION (OPTIMIZE FOR UNKNOWN)qui permettent, comme à travers l’utilisation de variables locales, de faire une optimisation générique à partir d’une distribution moyenne des valeurs des colonnes, et donc d’assurer la stabilité du plan, soit pour une variable, soit pour toutes les variables utilisées dans la requête.
Ces options sont très utiles dans les procédures stockées complexes, où le problème du parameter sniffing se fait le plus aigu, notamment lors de branchements conditionnels.
Prenons le cas de cette procédure « modulaire » :
CREATE PROCEDURE Person.GetContactsByWhatever
@NamePartType tinyint,
@NamePart nvarchar(50)
AS BEGIN
SET NOCOUNT ON
IF (@NamePartType = 1)
SELECT FirstName, LastName, EmailAddress
FROM Person.Contact
WHERE FirstName LIKE @NamePart
ELSE IF (@NamePartType = 2)
SELECT FirstName, LastName, EmailAddress
FROM Person.Contact
WHERE LastName LIKE @NamePart
ELSE IF (@NamePartType = 3)
SELECT FirstName, LastName, EmailAddress
FROM Person.Contact
WHERE EmailAddress LIKE @NamePart
END
Le but, louable au premier abord, est de créer une procédure générique.
Malheureusement, la première valeur envoyée dans @NamePart conditionne le plan d’exécution des trois instructions, pour trois colonnes différentes !
Dans ce cas, la recompilation sélective est très intéressante, car elle ne générera une compilation que de l’instruction utilisée (dans laquelle on se branche), au lieu d’une recompilation générale comme avec un WITH RECOMPILE.
Notons tout de même que la meilleure solution reste d’éviter la création de procédures génériques.
sp_recompile
La procédure stockée système sp_recompile permet de marquer une procédure ou un déclencheur pour être recompilée.
Dans les faits, elle supprime la procédure du cache.
Vous pouvez aussi indiquer une table ou une vue.
Dans ce cas, toutes les procédures référençant cet objet seront recompilées à leur prochaine exécution.
Cette procédure est aujourd’hui peu utile, SQL Server faisant ce travail lui-même, notamment invalidant automatiquement les procédures d’un objet qui vient d’être modifié.
Recompilations automatiques
Les recompilations ne sont pas toutes déclenchées volontairement. Pour plusieurs raisons, il ne serait pas raisonnable de conserver un plan d’exécution intouché, en cache, tout le long de la vie d’une instance (qui peut rester active des années sans être redémarrée).
Le serveur SQL vit : non seulement les structures sont susceptibles de changer, ce qui invalide le plan d’exécution, mais le contenu des tables évolue, entraînant des recalculs de statistiques, le contexte d’exécution des utilisateurs peut lui aussi changer, etc. Toutes choses entraînant un changement potentiel de plan d’exécution. SQL Server est attentif à ces modifications, et peut, lorsque le besoin s’en fait sentir, déclencher des recompilations automatiques, lors de l’exécution du code. Depuis SQL Server 2005, ces recompilations s’effectuent par instruction (statement-level recompilation) et n’affectent donc pas la procédure ou le batch tout entier.
Elles se produisent pour deux types de raisons :
Exactitude des données – la modification des structures sous-jacentes, comme l’ajout ou la suppression de colonnes de table, de contraintes, la suppression d’un index utilisé dans le plan, etc. ainsi que la modification d’options de session (notamment à l’intérieur de la procédure stockée). Les options qui peuvent modifier le résultat des requêtes ou la valeur des constantes, comme par exemple
SET ANSI_NULLS,SET CONCAT_NULL_YIELDS_NULL,SET DATEFORMAT, etc. peuvent provoquer des recompilations systématiques. Elles peuvent changer le contexte d’exécution, donc forcer le plan d’exécution à s’adapter à ce nouvel environnement ;Optimisation du plan – principalement lors d’un recalcul de statistiques. Le plan compilé comporte une valeur de seuil de recompilation, et teste à chaque exécution si le nombre de modifications dans la table dépasse ce seuil. Si c’est le cas, la requête est recompilée.
Les recompilations peuvent s’avérer coûteuses. Elles sont un mal (ou un bien) nécessaire, mais parfois, elles ralentissent inutilement l’exécution de procédures stockées.
Cela est généralement dû à de mauvaises pratiques de programmation, qui déclenchent des recompilations répétitives à chaque exécution de la procédure stockée, et même plusieurs fois par exécution. Nous avons parlé des options de sessions. D’autres éléments sont à considérer :
L’interpolation de code DML et de code DDL est susceptible de provoquer des recompilations : la modification de structure d’objets doit être répercutée dans le plan d’exécution des requêtes qui les référencent ;
La mauvaise utilisation de tables temporaires peut entraîner des recompilations. La situation depuis SQL Server 2005 est meilleure qu’en SQL Server 2000 : comme les recompilations s’effectuent maintenant instruction par instruction, beaucoup de recompilations dues aux tables temporaires ne se produisent plus, car le plan de toute la procédure n’est pas invalidé et le cache de chaque instruction peut être réutilisé.
Lorsque la table temporaire est créée, une recompilation de type « compilation déférée » (voir plus loin les événements de trace) est déclenchée. Ensuite, l’insertion, la mise à jour ou la suppression de lignes dans la table temporaire peut rapidement provoquer d’autres recompilations, pour prendre en compte les nouvelles cardinalités (la distribution des valeurs dans une colonne).
Une recompilation est générée sur une table temporaire à partir de six insertions sur une table vide. Exemple :
ALTER PROC dbo.testtemptable
@nbInserts smallint = 1
AS BEGIN
DECLARE @i smallint
SET @i = 1
CREATE TABLE #t (
id int identity(1,1) PRIMARY KEY NONCLUSTERED,
col char(8000) NOT NULL DEFAULT ('e')
)
WHILE @i <= @nbInserts BEGIN
INSERT INTO #t DEFAULT VALUES
SELECT * FROM #t WHERE col = 'e' OR id > 20
SET @i = @i + 1
END
END
GO
EXEC dbo.testtemptable
GO
Si vous tracez cette exécution avec le profiler, vous verrez un résultat ressemblant à la figure 9.2.
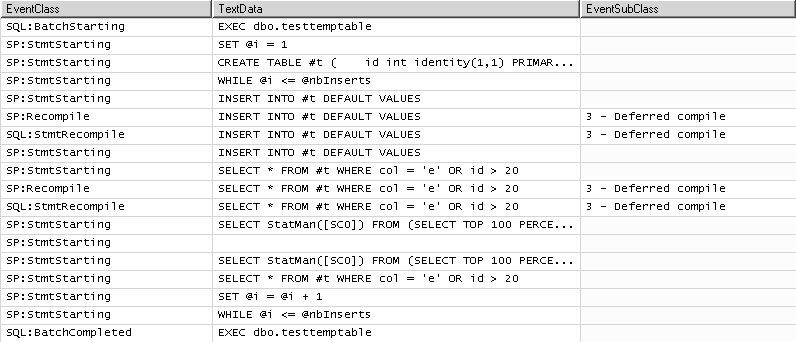
C’est-à-dire deux recompilations, pour compilation déférée. Si nous exécutons ensuite EXEC dbo.testtemptable 7, voici le résultat en figure 9.3 :
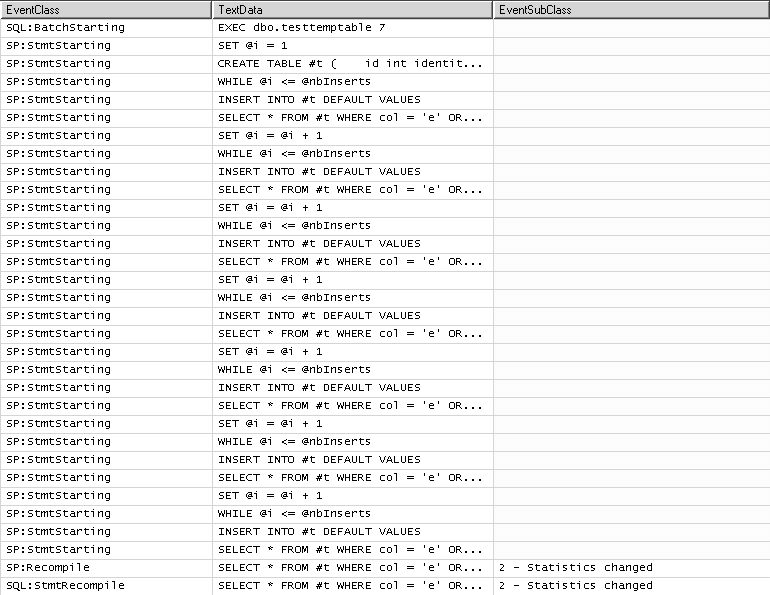
9.3 – Recompilations sur tables temporaires
Nous avons dû faire ici une requête SELECT sur la table temporaire un tout petit plus compliquée que nécessaire, parce que le comportement du cache sur des procédures stockées est bien meilleur qu’auparavant.
La recompilation se déclenche au bout de la sixième insertion dans la table, ce qui est le comportement normal de SQL Server.
À la deuxième exécution de la procédure, il n’y aura pas recompilation, l’instruction étant déjà cachée avec un plan valable. SQL Server est donc capable de gérer assez bien les recompilations dues aux tables temporaires. Cela ne veut pas dire que vous devez les utiliser sans modération. Évitez donc le recours exagéré aux tables temporaires. Elles sont souvent inutiles et peuvent être remplacées par des sous-requêtes, des expressions de table (CTE, common table expressions), ou, au pire, des variables de table pour les petits volumes.
Si vous êtes forcé de composer avec des tables temporaires, et que vous détectez par le profiler des recompilations fréquentes dues à des changements de cardinalité dans les tables, il vous reste deux options de requêtes avec lesquelles vous pouvez modifier la fréquence des recompilations : KEEP PLAN, et KEEPFIXED PLAN.
KEEP PLAN et KEEPFIXED PLAN
l’indicateur de requêtes KEEP PLAN modifie les seuils de compilation des tables temporaires (premiers seuils à 6 lignes modifiées, puis 500 lignes modifiées) qui deviennent alors identiques à ceux des tables permanentes.
Si les modifications apportées à des tables temporaires entraînent de nombreuses recompilations, essayez de placer cette option dans votre procédure, et vérifiez si cela diminue la fréquence de recompilation.
Exemple de syntaxe pour notre procédure :
SELECT *
FROM #t
WHERE col = 'e' OR id > 20
OPTION (KEEP PLAN)
L’indicateur KEEPFIXED PLAN est encore plus contraignant : il empêche simplement toute recompilation de l’instruction pour raison d’optimisation (nouvelles statistiques, changement de cardinalité, …
Tracer les recompilations
Vous pouvez détecter les recompilations à l’aide d’une trace, et des événements SP:Recompile et SQL:StmtRecompile. Ces événements vous indiquent, dans la colonne EventSubClass de la trace, pour quelle raison la recompilation a été déclenchée. Les valeurs possibles sont les suivantes :
| EventSubClass | Signification |
|---|---|
| 1 | La structure de l’objet a changé |
| 2 | Les statistiques ont changé |
| 3 | Compilation déférée : par exemple, lors de l’utilisation d’une table temporaire, les instructions de la procédure utilisant cette table ne peuvent être compilées au début de l’exécution de la procédure. Elles ne le pourront que lorsque la table sera effectivement crée. Cela déclenchera à ce moment une recompilation de ce type. |
| 4 | Une option de session a changé |
| 5 | Une table temporaire a changé |
| 6 | Un jeu de résultant distant (serveur lié) a changé |
| 7 | Une permission FOR BROWSE a changé |
| 8 | L’environnement de Query Notification a changé |
| 9 | Une vue partitionnée a changé |
| 10 | Les options de curseur ont changé |
| 11 | La recompilation a été demandée par l’option de requête RECOMPILE |
Cache des requêtes ad hoc
Le cache contient en réalité bien plus que les plans d’exécution des procédures stockées. Il existe trois parties principales du cache (cache stores) qui nous intéressent ici et qui stockent des résultats de compilation :
- Object Plans (CACHESTORE_OBJCP) – plans de procédures stockées, déclencheurs et fonctions ;
- SQL Plans (CACHESTORE_SQLCP) – plans de batches ;
- Bound Trees (CACHESTORE_PHDR) – arbres d’analyse d’une requête.
Elles comportent chacune une table de hachage qui permet de gérer les entrées du cache (une hash table composée de hash buckets).
Vous pouvez obtenir des informations sur les caches par la vue de gestion dynamique sys.dm_os_memory_cache_counters, et examiner les tables de hachage par la vue sys.dm_os_memory_cache_hash_tables et enfin les hash buckets par sys.dm_os_memory_cache_entries.
Il y a également plusieurs types d’objets dans le cache, les deux qui nous intéressent ici sont les plans compilés (Compiled Plans, CP) et les plans d’exécution (Execution Plans, MXC).
La requête suivante vous donne la taille de ces caches :
SELECT
Name,
Type,
single_pages_kb,
single_pages_kb / 1024 AS Single_Pages_MB,
entries_count
FROM sys.dm_os_memory_cache_counters
WHERE type in ('CACHESTORE_SQLCP', 'CACHESTORE_OBJCP',
'CACHESTORE_PHDR')
ORDER BY single_pages_kb DESC
Les plans compilés représentent la compilation d’une procédure ou d’un batch de requêtes (c’est-à-dire d’ordres SQL envoyés en un seul lot depuis le client). S’il s’agit d’une procédure (procédure stockée, fonction, déclencheur), il est stocké dans CACHESTORE_OBJCP, s’il s’agit d’un batch, il ira dans CACHESTORE_SQLCP.
Les plans d’exécution sont en quelque sorte des instances des plans compilés, ils sont générés rapidement, à l’exécution, à partir d’un plan compilé.
Il y a un plan d’exécution par utilisateur lançant la procédure ou le batch. Vous pouvez inspecter ces plans à l’aide de la fonction sys.dm_exec_cached_plan_dependent_objects, à laquelle vous passez en paramètre un plan_handle venant de sys.dm_exec_cached_plans.
Si la procédure est en cours d’exécution plusieurs fois simultanément, vous trouverez plusieurs références au même plan_handle.
Les plans compilés contiennent un tableau d’instructions SQL. Chaque ordre SQL dans la procédure ou le batch sont compilés séparément dans des Cstmt, ou Compiled Statements. Les plans d’exécution génèrent des Xstmts, les versions runtime des Cstmt[^33].
Voici une requête pour voir la taille et l’utilisation des différents objets :
SELECT
COUNT(*) as cnt,
SUM(size_in_bytes) / 1024 as total_kb,
MAX(usecounts) as max_usecounts,
AVG(usecounts) as avg_usecounts,
CASE GROUPING(cacheobjtype)
WHEN 1 THEN 'TOTAL'
ELSE cacheobjtype
END AS cacheobjtype,
CASE GROUPING(objtype)
WHEN 1 THEN 'TOTAL'
ELSE objtype
END AS objtype
FROM sys.dm_exec_cached_plans
GROUP BY cacheobjtype, objtype
WITH ROLLUP
Le code de la procédure ou du batch est stocké dans un cache à part, le SQL Manager Cache (SQLMGR). Il s’agit d’un stockage différent du plan réellement utilisé à l’exécution.
Vous pouvez voir les informations générales de ce cache à l’aide de cette requête :
SELECT *
FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR'
Pourquoi maintenir le code de la requête séparément du plan compilé ?
Simplement parce que ce plan peut changer, selon l’état de la session, c’est-à-dire le contexte d’exécution. Il est important de s’y arrêter, car cela influe sur la possibilité qu’a SQL Server de réutiliser un plan en cache.
Réutilisation des plans
Imaginons que nous exécutions le même code, dans deux sessions qui comportent des options de session différentes (SET …
SET CONCAT_NULL_YIELDS_NULL ON
GO
SELECT TOP 10 FirstName + ' ' + MiddleName + ' ' + LastName
FROM Person.Contact
GO
SET CONCAT_NULL_YIELDS_NULL OFF
GO
SELECT TOP 10 FirstName + ' ' + MiddleName + ' ' + LastName
FROM Person.Contact
GO
Ou, imaginons que nous avons deux utilisateurs, Paul et Isabelle, qui sont déclarés dans la base avec deux schémas par défaut différents (par exemple Person et HumanResources).
S’ils exécutent tous deux un code identique, qui ne référence pas le schéma de l’objet, un plan d’exécution différent doit être généré, même si l’objet qui sera touché est le même, simplement parce que SQL Server ne sait pas à l’avance quel va être le bon objet.
En vertu du mécanisme de résolution de nom, un objet appartenant au schéma par défaut sera d’abord recherché, et s’il n’est pas trouvé, SQL Server cherchera un objet appartenant au schéma dbo. Exemple :
CREATE TABLE dbo.test (TestId int)
GO
ALTER USER isabelle WITH DEFAULT_SCHEMA = Person
ALTER USER paul WITH DEFAULT_SCHEMA = HumanResources
GO
CREATE TABLE dbo.test (TestId int)
GO
GRANT SELECT ON dbo.test TO paul
GRANT SELECT ON dbo.test TO isabelle
GO
EXECUTE AS USER = 'paul'
SELECT CURRENT_USER
GO
SELECT * FROM test
GO
REVERT
GO
EXECUTE AS USER = 'isabelle'
SELECT CURRENT_USER
GO
SELECT * FROM test
GO
REVERT
GO
Combien avons-nous de plans ? Vous trouverez sur la figure 9.4 le résultat de la requête
SELECT st.text, qs.sql_handle, qs.plan_handle
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) st
ORDER BY qs.sql_handle
exécutée après les deux exemples ci-dessus.

Vous voyez que pour le même sql_handle, vous avez chaque fois deux plan_handle. Cela signifie que SQL Server a généré deux plans différents, et qu’il a donc stocké deux plans en cache.
Vous pouvez aussi le constater en traçant avec le profiler l’événement sp:CacheInsert.
Afin de vérifier pour quelle raison (quel attribut du plan) des plans différents ont été créés, vous pouvez vous baser sur la vue sys.dm_exec_plan_attributes, comme ceci par exemple (en passant un sql_hande trouvé) :
SELECT st.text, qs.sql_handle, qs.plan_handle, pa.attribute, pa.value
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.plan_handle) st
OUTER APPLY sys.dm_exec_plan_attributes(qs.plan_handle) pa
WHERE qs.sql_handle = 0x020000002F5CC820E0CC946DD76094543CF7AA299904C81A
AND pa.is_cache_key = 1
ORDER BY pa.attribute
Ce qu’il faut comprendre ici, c’est que SQL Server cherche à réutiliser autant que possible les plans d’exécution en cache, car le recalcul de plans peut être très pénalisant.
Nous venons de voir que certaines conditions invalident pourtant le plan en cache et obligent SQL Server à compiler à nouveau le batch ou la procédure. Il faut éviter autant que possible de provoquer de telles situations.
Les deux cas que nous avons testés ci-dessus sont les plus courants :
Un changement d’options de session en cours de travail modifie le contexte d’exécution. Des options comme ANSI_NULLS, ANSI_DEFAULTS, CONCAT_NULL_YIELDS_NULL, ARITHABORT, DATEFIRST, DATEFORMAT, LANGUAGE, QUOTED_IDENTIFIER, etc. peuvent empêcher la réutilisation d’un plan, parce qu’elles influent sur les comparaisons, et qu’elles modifient potentiellement la valeur des littéraux exprimés dans la requête. SQL Server évalue très tôt dans la phase de compilation la valeur de ces littéraux (une fonctionnalité nommée constant folding). Si une option est modifiée, qui peut changer cette valeur déjà évaluée, le code doit être compilé à nouveau ;
Lorsqu’un objet n’est pas complètement identifié par son schéma, SQL Server ne peut pas garantir que l’appel par des utilisateurs dont le schéma par défaut est différent, va référencer le même objet, il doit donc recompiler.
Deux conseils s’imposent donc :
1. Maintenez des états de session consistants en affectant les options à la connexion et éviter de les changer en cours de route, surtout à l’intérieur des procédures stockées (le SET NOCOUNT n’entre pas dans cette catégorie, il ne provoque aucune recompilation, puisqu’il ne change pas le comportement des requêtes) ; 2. préfixez toujours vos objets par leur nom de schéma.
En ce qui concerne les options de session, attention aux différentes variétés de bibliothèques client. Les anciennes méthodes de connexion, telles que ODBC, ne placent pas par défaut les mêmes valeurs d’option que les méthodes plus modernes, comme ADO.NET.
Pour savoir quelles sont les valeurs des options de session, vous pouvez utiliser la commande DBCC USEROPTIONS, ou les événements Session / ExistingConnection et Security Audit / Audit Login.
La différence entre le plan compilé et le plan d’exécution peut être observé via la vue sys.dm_exec_query_stats, qui référence le plan compilé dans la colonne sql_handle et le plan d’exécution dans la colonne plan_handle. Les handle sont des hachages MD5 générés à partir du plan entier, ils sont donc garantis uniques par plan. Ils peuvent être passés à la fonction sys.dm_exec_sql_text pour voir le contenu du plan.
Lorsque nous avons extrait dans les requêtes précédentes des plans d’exécution du cache, à l’aide de la vue sys.dm_exec_cached_plans et de la colonne plan_handle, nous avions accès à la totalité du plan compilé, et non aux Cstmt individuels. Cette vision était celle d’un cache particulier, vous pouvez en faire l’expérience avec cette requête d’exemple :
DBCC FREEPROCCACHE
GO
SET CONCAT_NULL_YIELDS_NULL ON
GO
SELECT TOP 10 FirstName + ' ' + MiddleName + ' ' + LastName
FROM Person.Contact
GO
SET CONCAT_NULL_YIELDS_NULL OFF
GO
SELECT TOP 10 FirstName + ' ' + MiddleName + ' ' + LastName
FROM Person.Contact
GO
-- plusieurs plan_handle pour le même sql_handle
SELECT
cp.usecounts,
cp.size_in_bytes,
st.text
FROM sys.dm_exec_cached_plans cp
OUTER APPLY sys.dm_exec_sql_text (cp.plan_handle) st
JOIN sys.dm_exec_query_stats qs ON qs.plan_handle = cp.plan_handle
GO
Cache des requêtes adhoc
Nous l’avons vu, les procédures ne sont pas seules à être cachées, tout plan d’exécution d’une requête isolée est potentiellement réutilisable. Une première réaction serait de penser que cette fonctionnalité rend la procédure stockée moins intéressante, puisque toutes les requêtes peuvent profiter d’un cache de leur plan d’exécution. Ce n’est pas vraiment le cas, la procédure reste nettement plus performante, non seulement par les avantages que nous avons déjà abordés (diminution du trafic réseau, centralisation du code, sécurité facilitée), mais aussi parce que le cache de requêtes est soumis à quelques contraintes. Nous allons le voir.
Lorsqu’une requête ad-hoc (c’est-à-dire un ordre SQL composé par le client, par opposition à du code stocké sur le serveur comme une procédure) est envoyée au serveur, SQL Server essaie de trouver une correspondance de texte de requête dans le cache SQLMGR. Cette correspondance est recherchée en comparant le hachage généré par la requête entrante avec les hachages présents dans le cache, puisque ces chaînes de hachages représentent un résumé de toute la requête cachée. Cela permet d’effectuer une recherche très rapide, mais cela signifie aussi que la moindre différence de syntaxe invalide la recherche, puisqu’elle produit un résultat de hachage différent. Une espace de plus, une différence de casse dans la requête (même sur une serveur dont la collation par défaut est insensible à la casse, cela n’a pas de rapport avec la gestion du cache) suffit à générer une nouvelle entrée dans le cache. Vérifions-le simplement :
DBCC FREEPROCCACHE
GO
SELECT * FROM dbo.test
GO
SELECT * FROM dbo.test
GO
SELECT * FROM dbo.TEST
GO
select * from dbo.test
GO
SELECT
cp.usecounts,
cp.size_in_bytes,
st.text
FROM sys.dm_exec_cached_plans cp
OUTER APPLY sys.dm_exec_sql_text (cp.plan_handle) st
JOIN sys.dm_exec_query_stats qs ON qs.plan_handle = cp.plan_handle
GO
Le code ci-dessus provoque l’insertion de quatre entrées de cache, comme nous pouvons le constater dans la figure 9.5.

Attention
la correspondance avec un plan adhoc caché n’est possible que si les objets sont préfixés par leur schéma.
Comme pour le cache de procédure, ces plans d’exécution ne sont libérés qu’en cas de besoin mémoire.
Mais ce fonctionnement est valable même en considérant des valeurs constantes différentes, passées dans les clauses WHERE pour la recherche ?
En d’autres termes, des requêtes comme :
SELECT * FROM Person.Contact WHERE ContactId = 20
GO
SELECT * FROM Person.Contact WHERE ContactId = 40
GO
sont-elles cachées séparément ? Cela dépend. Dans cet exemple, un examen de sys.dm_exec_query_stats montre ceci :
(@1 tinyint)SELECT * FROM [Person].[Contact] WHERE
[ContactId][=@1](mailto:%3D@1)
Ce qui signifie que SQL Server a transformé la requête avant de la mettre dans le cache, pour remplacer les valeurs littérales par un paramètre. Dans certains cas, SQL Server peut donc « paramétrer » la requête, et transformer la valeur passée comme critère de recherche en paramètre, en interne. Cela permet de réutiliser le plan si d’autres paramètres sont passés. Ce mécanisme s’appelait paramétrage automatique (auto-parameterization) en SQL Server 2000, et est maintenant nomméparamétrage simple (simple parameterization).
Le comportement par défaut de SQL Server fait qu’un nombre limité de requêtes peuvent être ainsi paramétrées. Par exemple, les deux requêtes ci-dessous sont cachées séparément sur SQL Server 2005 sp2 :
SELECT * FROM Person.Contact WHERE LastName = 'Allen'
GO
SELECT * FROM Person.Contact WHERE LastName = 'Ackerman'
GO
Nous avons vu que la valeur de LastName peut ici fortement influencer le plan d’exécution, déclenchant soit un seek, soit un scan de l’index.
L’exemple précédent, où le paramétrage avait eu lieu, était plus facile : ContactId est la clé primaire de la table, donc sa valeur est garantie unique.
Une recherche d’égalité est donc garantie de retourner une seule ligne, et qui plus est dans une recherche par un index clustered (option par défaut à la création d’une clé primaire).
Le plan d’exécution ne changera pas, quel que soit la valeur passée en paramètre. SQL Server ne cache donc qu’un plan qu’il considère « safe », c’est-à-dire qui va pouvoir répondre à pratiquement tous les cas de valeur du paramètre. De plus, il n’essaie même pas de paramétrer des requêtes qui comportent des constructions particulières, pour certaines très courantes, comme des jointures ou des sous-requêtes[^34]. Vraiment pas de quoi concurrencer une procédure stockée…
Notons que la réutilisation du cache de requêtes paramétrées est plus souple avec la syntaxe, car elle ne base plus sa recherche sur le même mécanisme de comparaison de hachage.
Une requête paramétrée sera alors « rationalisée « pour correspondre à la même requête comportant des espaces ou des retours chariot différents. Elle reste toutefois sensible à la casse.
Pour généraliser le paramétrage, vous disposez éventuellement d’une option de base de données qui force SQL Server à paramétrer toutes les requêtes :
ALTER DATABASE AdventureWorks SET PARAMETERIZATION FORCED
– pour revenir à l’état par défaut :
ALTER DATABASE AdventureWorks SET PARAMETERIZATION SIMPLE
En passant en paramétrage forcé (Forced Parameterization), toutes les valeurs littérales rencontrées dans une requête sont converties en paramètres. La requête ci-dessus sera alors stockée dans le cache avec la syntaxe suivante :
(@0 varchar(8000))select * from Person.Contact where LastName = @0
Apparemment utile, c’est option n’est pas à activer à la légère, car le paramétrage implique un effort plus important de SQL Server, aussi bien à la génération du plan d’exécution qu’à la recherche de correspondances dans le cache. Elle peut aussi provoquer la conservation et la réutilisation de plans non optimaux, puisque les limites du paramétrage simple servent justement à générer des plans différents lorsque c’est nécessaire.
Elle n’est donc pas la panacée. Rien ne remplace la simplicité d’une procédure stockée.
Vous noterez au passage que le paramètre généré est de type varchar(8000), alors que la colonne recherchée est un nvarchar(50), le type de la colonne n’est pas vérifié par SQL Server, qui applique le type du littéral, et la taille maximum du type de données.
Cette opération est appelée bucketization. Elle est forcée par le serveur dans ce cas, mais vous avez la possibilité de paramétrer votre requête dans votre code client (par exemple en utilisant la collection Parameters de l’objet SQLCommand en ADO.NET avec des types de données explicites), et ainsi d’optimiser le type de données du paramètre, pour une commande que vous allez réutiliser plusieurs fois.
SQL Server 2008 intègre une option de serveur nommée « optimize for ad hoc workloads », qui vous permet de diminuer la consommation de mémoire en cache de plan, lorsque votre serveur est principalement utilisé avec des requêtes dynamiques, non paramétrées. Pour l’activer, exécutez ce code :
EXEC sp_configure 'show advanced options',1
RECONFIGURE
EXEC sp_configure 'optimize for ad hoc workloads',1
RECONFIGURE
9.2.2 Paramétrer le SQL dynamique
Une facilité est offerte pour l’exécution paramétrée du SQL dynamique. Au lieu d’utiliser la commande EXECUTE(), qui se contente d’évaluer et d’envoyer l’instruction SQL telle quelle, la procédure stockées système sp_executesql permet de déclarer des paramètres dans la chaîne et de les envoyer à chaque appel, paramétrant ainsi explicitement le plan d’exécution. Voici un exemple qui présente les deux solutions :
DBCC FREEPROCCACHE
GO
DECLARE @sql varchar(8000)
SET @sql = 'SELECT * FROM Person.Contact WHERE LastName =
''Allen'''
EXECUTE (@sql)
SET @sql = 'SELECT * FROM Person.Contact WHERE LastName =
''Ackerman'''
EXECUTE (@sql)
GO
DECLARE @sql nvarchar(4000)
SET @sql = 'SELECT * FROM Person.Contact WHERE LastName =
@LastName'
EXECUTE sp_executesql @sql, N'@LastName NVARCHAR(80)', @LastName =
'Allen'
EXECUTE sp_executesql @sql, N'@LastName NVARCHAR(80)', @LastName =
'Ackerman'
GO
SELECT
cp.usecounts,
cp.size_in_bytes,
st.text
FROM sys.dm_exec_cached_plans cp
OUTER APPLY sys.dm_exec_sql_text (cp.plan_handle) st
JOIN sys.dm_exec_query_stats qs ON qs.plan_handle = cp.plan_handle
GO
Bien sûr, autant que possible, préférez la syntaxe avec sp_executesql.
Il est à noter qu’une fonctionnalité similaire est proposée par les bibliothèques d’accès client, qui permettent de « préparer » le code SQL à envoyer, pour favoriser la réutilisation du plan d’exécution. OLEDB expose l’interface IcommandPrepare pour ce faire. N’utilisez pas systématiquement cette fonctionnalité, elle est souvent plus coûteuse qu’utile. Réservez-la à des exécutions multiples – au moins plus de trois fois – de la même requête.