Les compteurs de performances
32 minutes à lire
Le moniteur système
Le moniteur système, ou moniteur de performance, n’est pas propre à SQL Server. C’est un utilitaire de supervision intégré à Windows, qui est comme le moniteur cardiaque du système. Il vous permet de suivre en temps réel tous les compteurs – des données chiffrées – indiquant le comportement de votre serveur. Un certain nombre d’application, dont SQL Server, ajoutent leur propre jeu de compteurs à ceux proposés par Windows. Vous pouvez ainsi, dans la même interface, suivre les signes vitaux de Windows et de SQL Server.
Vous trouvez le moniteur système soit dans le menu Windows, sous Outils d’administration / Performances, soit en lançant l’exécutable perfmon.exe.
À l’ouverture, quelques compteurs sont déjà présélectionnés, il vous appartient de les retirer si vous n’en avez pas besoin, et de choisir les vôtres.
Vous pouvez soit afficher l’évolution des compteurs en temps réel, soit enregistrer les mesures dans un fichier journal.
Cette dernière solution est idéale pour construire une baseline. L’affichage peut être graphique (courbes d’évolution), utile pour les compteurs dont il est intéressant de suivre la progression dans le temps, ou sous forme de tableau, pour obtenir la valeur actuelle précise. Vous pouvez également, pour chaque compteur, modifier l’échelle de sa ligne dans le graphe, afin de pouvoir mélanger des unités de mesures diverses sur le même affichage, ainsi que la couleur et l’épaisseur de son trait.
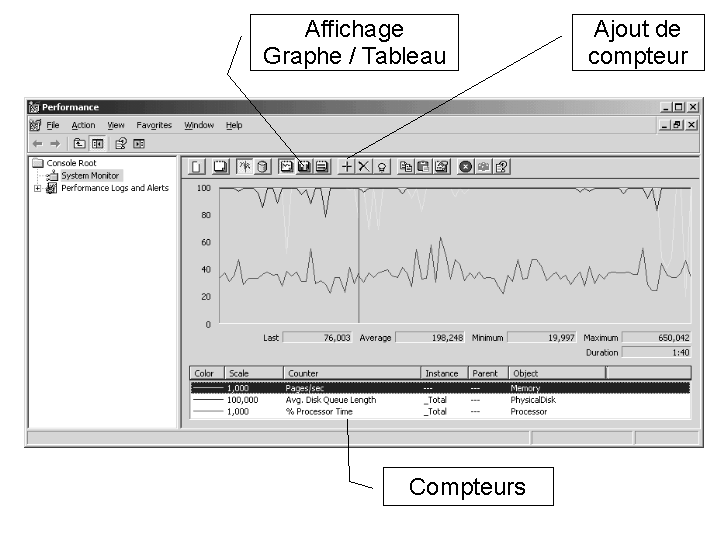
Attention aux différences d’échelle d’affichage dans le graphe. Il est facile de se méprendre en comparant deux mesures à des échelles différentes. Vous pouvez modifier la valeur d’échelle dans les propriétés du compteur, onglet Data, liste de choix scale.
Pour ajoutez des compteurs, cliquez sur le bouton affichant le signe + dans la barre d’outils, ou utilisez la combinaison de touches CTRL+I.
Vous obtenez ainsi la fenêtre de sélection de compteurs.
Vous pouvez sélectionner de quelle machine vous voulez obtenir les compteurs, avec la syntaxe \\NOM_MACHINE.
Lorsque vous sélectionnez un compteur, le bouton explain… vous permet d’obtenir une petite description.
Les compteurs sont regroupés par objets, et certains s’appliquent à des instances. L’objet est une collection de compteurs qui s’appliquent au même sous-système, par exemple les processeurs (CPU), les disques physiques, la mémoire vive, des modules de SQL Server,… Les instances représentent les unités de ces sous-systèmes que le compteur mesure.
Par exemple, l’objet processeur a autant d’instances que le système compte de processeurs logiques (deux instances pour un Dual Core ou un processeur hyper-threadé), ou l’objet disque logique a autant d’instances qu’il existe de partitions.
Si vous voulez recueillir un compteur pour toutes les instances d’un objet, vous pouvez soit sélectionner le bouton radio all instances…, soit choisir une instance qui regroupe les autres, la plupart du temps présente, et qui porte le nom _Total.
Pour certains éléments, il peut être intéressant d’afficher à la fois un compteur par instance, et un compteur total.
Vous obtenez une bonne perception du comportement du multitâche, par exemple, en visualisant une ligne par CPU individuel et une moyenne sur une ligne dont vous augmentez l’épaisseur. Cela vous permet en un coup d’oeil de juger de l’équilibre de la charge de travail accordé par le système à chaque CPU.
Chaque objet dispose de compteurs spécifiques, qui sont les pourvoyeurs d’informations chiffrées. Ces informations sont exprimées soit en valeur courante (par exemple : LogicalDisk/Current Disk Queue Length), en moyenne (LogicalDisk/Avg Disk Queue Length), en pourcentage (LogicalDisk/% Disk Read Time) ou en totaux cumulés (Memory/Committed Bytes), soit en quantité par secondes (LogicalDisk/Disk Reads/sec).
Comme vous pouvez afficher dans la même fenêtre des compteurs provenant de machine différentes, le contexte complet du compteur est constitué de quatre parties : \Ordinateur\Objet(Instance)\Compteur.
Il nous est arrivé, lorsque nous avions deux écrans à disposition, de conserver une fenêtre du moniteur système ouverte en permanence sur notre second écran, avec quelques compteurs essentiels montrant l’état d’un serveur SQL. Dans ce cas, nous choisissions un délai de rafraîchissement de 5 ou 10 secondes, afin de ne pas trop impacter le serveur.
Il est à noter qu’une utilisation du moniteur sur une machine cliente est moins pénalisante qu’une utilisation locale au serveur. Dans ce cas, nous cachions tous les éléments d’affichage inutiles, pour ne conserver qu’une vue de rapport, comme reproduit sur la figure 5.13.
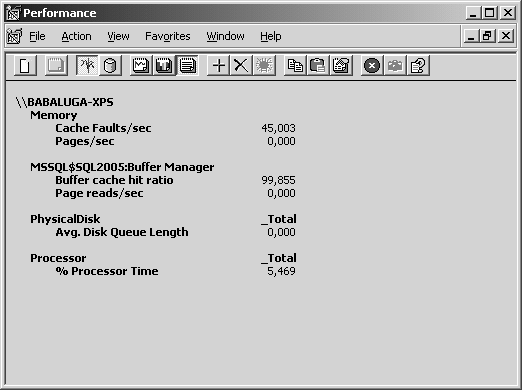
Lorsque vous avez obtenu une vision satisfaisante, et que vous avez choisi les bons compteurs, vous pouvez sauver cette configuration dans un fichier de configuration de console (Le moniteur de performance est un snap-in de l’outils Windows MMC, Microsoft Management Console), portant l’extension .msc.
Cela vous permet de rouvrir très rapidement des jeux de compteur.
Vous pouvez vous faire une deuxième fenêtre montrant l’activité des processeurs en affichage graphe.
Voici un script WSH (Windows Script Host) que vous pouvez utiliser pour lancer en une seule commande plusieurs fenêtres de moniteur à partir de fichiers .msc (deux dans l’exemple) :
Option Explicit
Dim oWsh : Set oWsh = CreateObject("WScript.Shell")
oWsh.Run "mmc ""C:\mypath\CPU.msc"""
oWsh.Run "mmc ""C:\mypath\SQL MEMORY AND DISK.msc"""
Set oWsh = Nothing
Nous allons passer en revue les indicateurs utiles pour suivre l’activité de SQL Server.
Choisir les bons compteurs
Pour obtenir des informations sur les performances de SQL Server, vous devez panacher des compteurs fourni par le système d’exploitation, et des compteurs propres à SQL Server. Certains compteurs du système d’exploitation ne peuvent vous donner des informations précises, par exemple sur l’utilisation du cache de mémoire.
Nous avons parlé de la couche SQLOS. SQL Server vous fournit donc des compteurs spécifiques qui vous permettent d’explorer plus en détails ce que fait SQLOS. Nous allons séparer les compteurs essentiels, qui vous donnent des informations vitales sur la santé de votre serveur, des compteurs utiles.
Les compteurs essentiels
MSSQL:Buffer Manager\Buffer cache hit ratio : ce compteur indique le pourcentage de pages lues par le moteur de stockage, qui ont pu être servies depuis le cache de données (le buffer), sans accéder au disque, calculé sur les quelques derniers milliers de pages demandées. Ce ratio doit être élevé : moins SQL Server doit accéder au disque, plus il sera rapide. On considère dans une application OLTP à volumétrie moyenne, que cette valeur doit être en dessus de 97 ou 98 %, ce qui est déjà peu. Un bon chiffre est en-dessus de 99,7 %. Si le ratio est bas, et que vous observez également une activité et un file d’attente importantes sur le disque, augmentez la mémoire vive de votre système (ou cherchez des scans de table qui peuvent être éliminés par la création d’index).
MSSQL:Databases\Transactions/sec : nombre de transactions par seconde. Le choix de l’instance de compteur vous permet d’afficher toutes les transactions, ou les transactions dans un contexte de base particulier, ce qui est utile pour tracer l’activité comparative de vos bases de données, et l’activité dans tempdb. Une utilisation régulière de ce compteur vous permet de connaître l’activité moyenne de votre serveur, à travers le temps et durant les périodes de la journée, ainsi que de détecter les augmentations de charge.
Une valeur élevée de transactions par seconde, avec des résultats raisonnables d’autres compteurs (utilisation du disque, pourcentage d’activité des processeurs) indique une machine qui travaille bien. Un bon signe de l’effectivité de vos efforts d’optimisation d’un serveur est l’augmentation du nombre de transactions par seconde, liée à la diminution de la charge des processeurs.
Une quantité importante de transactions dans tempdb indique généralement soit un recours fréquent aux tables temporaires dans le code, soit un fonctionnement en niveau d’isolation snapshot.
Vous pouvez vérifier que cette activité n’est pas dûe à une création de tables de travail internes, destinées à résoudre des plans de requête, en observant le compteur MSSQL:Acces Methods\Worktables Created/sec, qui indique le nombre de tables de travail créées par seconde.
Les tables de travail stockent des résultats intermédiaires lors de l’exécution de code SQL. Vous pouvez aussi vous baser sur le compteur MSSQL:General Statistics\Active Temp Tables pour connaître le nombre de tables temporaires dans tempdb, ou MSSQL:General Statistics\Temp Tables Creation Rate pour une quantité de tables temporaires utilisateur créées par seconde. Référez-vous à la section dédiée à tempdb pour plus de détails.
MSSQL:General Statistics\Temp Tables Creation Rate: indique le nombre de tables temporaires utilisateurs créées par seconde. Le compteur MSSQL:General Statistics\Temp Tables For Destruction retourne le nombre de tables temporaires marquées pour suppression pour le thread de nettoyage. Ces compteurs vous donnent une bonne idée du poids des tables temporaires dans votre code SQL, et des problèmes potentiels qu’elles peuvent produire (contention des tables de métadonnées dans tempdb, par exemple, voir section 8.3.1).
PhysicalDisk\Avg. Disk Queue Length : longueur moyenne de la file d’attente sur un disque. Le disque dur étant à accès séquentiel (une seule tête de lecture, donc une seule lecture/écriture à la fois), les processus qui veulent accéder au disque lorsque celui-ci est déjà en utilisation, sont placés dans une file d’attente.
Il s’agit donc de temps perdu à faire la queue, comme aux caisses d’un supermarché. Dans l’idéal, ce compteur devrait toujours être à 0, voire 1, avec des possibilités de pointes. Si la valeur est de façon consistante à 2 ou plus, vous avez un goulot d’étranglement sur le disque. Que faire ? Les possibilités sont, dans l’ordre logique d’action :
- diminuer les besoins de lecture sur le disque, en optimisant les requêtes, ou la structure physique de vos données, notamment en créant des index pour éviter les scans ;
- ajouter de la RAM, pour augmenter la taille du buffer, et diminuer les besoins de lecture sur le disque ;
- déplacer les fichiers de base de données ou de journal de transaction les plus utilisés, sur d’autres disques, pour partager la charge : faire du scale-out;
- utiliser un disque plus rapide, avec un meilleur temps d’accès, un contrôleur plus rapide, ou utiliser un sous-système disque plus performant (SAN, stripe, …)
Processor% Processor Time : Pourcentage d’utilisation des processeurs logiques (deux instances sur un Dual Core). La valeur retournée est soit la moyenne des tous les processeurs si vous affichez toutes les instances, soit par instance.
C’est le compteur de base pour avoir une idée de départ de la charge de votre serveur. Une machine dont les processeurs sont constamment proches du 100 % a un problème. Soit elle a atteint les limites de ses capacités, et il faut donc songer à acquérir du nouveau matériel, que ce soit en scale-up ou en scale-out (répartition de charge), soit un élément du système entraîne une surcharge. Vous amener à identifier cet élement est un des objectifs de ce livre.
Il est important de comprendre qu’une forte activité des processeurs ne signifie pas que la puissance ou la quantité des CPUs doit être augmentée. Le travail du processeur est influencé par tous les autres sous-systèmes. Si le disque est inutilement sollicité, ou trop lent, si la file d’attente sur le disque implique de nombreuses attentes de threads, si la mémoire vive fait défaut et entraîne donc une plus forte utilisation du disque, etc. les CPUs devront travailler plus. Donc, le temps processeur n’est que la partie émergée de l’iceberg, vous devez inspecter toutes les raisons possibles de cette surcharge de travail, avant de tirer vos conclusions.
Les compteurs utiles
Memory\Pages/sec : indique le nombre de pages de mémoire (dans le sens Windows du terme) qui sont écrites sur le disque, ou lues depuis le disque. Un nombre élevé (par exemple plus de 2 500 pages par secondes, de façon consistante sur un serveur de puissance moyenne, peut indiquer un manque de mémoire. À corréler avec les compteurs de cache de SQL Server, et l’activité disque.
MSSQL:Access Methods\Forwarded Records/sec : Indique un nombre le lignes lues via un renvoi d’enregistrement par secondes. Cela peut permettre de détecter un trop grand nombre de renvois d’enregistrements[^13].
Sur une table sans index clustered, le moteur de stockage crée des pointeurs de renvoi lorsque la taille d’une ligne modifiée augmente (parce qu’elle contient des colonnes de taille variable), et qu’elle ne peut plus tenir dans sa page originelle.
Ce pointeur reste en place jusqu’à un shrink de la base de données (ou jusqu’à ce que la ligne diminue suffisamment de taille pour réintégrer sa page d’origine).
Un trop grand nombre de renvois diminue les performances d’IO, à cause de l’étape supplémentaire de lecture du pointeur, et de déplacement sur son adresse.
Cela ne devient problématique sur une table que lorsqu’un bon pourcentage de la table contienne des renvois d’enregistrements.
Vous pouvez détecter ces tables à l’aide de la fonction de gestion dynamique sys.dm_db_index_physical_stats :
SELECT
OBJECT_NAME(object_id) as ObjectName, index_type_desc,
record_count, forwarded_record_count,
(forwarded_record_count / record_count)\*100 as
forwarded_record_ratio
FROM sys.dm_db_index_physical_stats(DB_ID('AdventureWorks'),
NULL, NULL, NULL, DEFAULT)
WHERE forwarded_record_count IS NOT NULL;
Attention
le dernier paramètre (mode) doit être indiqué à une valeur différente deLIMITEDouNULL(qui équivaut àLIMITED), sinon toutes les valeurs de la colonneforwarded_record_countseront renvoyées àNULL.
Ne vous inquiétez pas d’un nombre raisonnable de Forwarded Records/sec, cela peut arriver dans des tables temporaires sur tempdb. Vérifiez alors le nombre de tables temporaires, et le nombre de transactions dans tempdb. Si la valeur ne correspond pas à une activité de tempdb, cherchez dans votre bases utilisateurs quelles sont les tables heap qui contiennent des renvois d’enregistrements, à l’aide de la fonction ci-dessus.
Pour diminuer le nombre de renvois, vous pouvez soit faire un shrink (DBCC SHRINKDATABASE ou DBCC SHRINKFILE) de votre base de données, ce qui est une mauvaise solution en soi, sauf si vous faites un shrink sans diminuer la taille physique du fichier, à l’aide de
l’option NOTRUNCATE :
DBCC SHRINKDATABASE (AdventureWorks, NOTRUNCATE);
ce qui réorganise les pages sans diminuer la taille des fichiers.
La vraie bonne solution reste toutefois de réorganiser la table en créant un index clustered, que vous pouvez supprimer ensuite si vous tenez absolument à conserver une table heap (il n’y aurait pas de raison, la table clustered est à recommander)[^14].
Attention
les augmentations et diminutions automatiques des fichiers de données et de journal sont très pénalisantes pour les performances, et génèrent une fragmentation importante. Elles sont à éviter.
MSSQL:Access Methods\Full Scans/ses: indique un nombre de scans de table (table heap ou index clustered) par seconde. Le scan de table n’est pas un problème en soi sur les petites tables, il est en revanche très pénalisant sur les tables à partir d’une taille raisonnable (s’entend en nombre de pages. Une table contenant beaucoup de lignes contenant des colonnes de petite taille peut provoquer moins de lectures qu’une table ayant moins de lignes, mais contenant des colonnes plus grandes). Ce compteur est utile pour détecter un manque d’index ou des requêtes mal écrites. Un scan provient soit d’un manque index utile pour résoudre la clause de recherche (qu’il soit absent ou trop peu sélectif), soit de la présence de requêtes qui ne filtrent pas (ou mal) les données, par exemple de requêtes sans clause WHERE. Pour plus de détails, reportez-vous au chapitre 6.
MSSQL:Access Methods\Page Splits/sec: indique un nombre de séparations (split) de page par seconde.
Un nombre élevé de page splits indique que des index font face à d’intensives réorganisations dûes à des modifications de données sur leurs clés.
Cela pourra vous pousser à utiliser un FILLFACTOR (voir section 6.1) plus élevé sur ces index, ou à modifier votre stratégie d’indexation.
Pour chercher sur quels index les splits se sont produits, la fonction de gestion dynamique sys.dm_db_index_operational_stats peut vous donner des pistes.
Pour plus de détails, reportez-vous au chapitre 6.
MSSQL:Access Methods\Table Lock Escalations/sec: retourne un nombre d’escalade de verrous par seconde. Pour plus d’information sur les escalade de verrous, reportez-vous au chapitre 7.
Pour identifier quelles requêtes peuvent provoquer une escalade de verrous, vous pouvez tenter de corréler les pics de ce compteur avec une trace SQL (voir la corrélation de journal de compteur et de trace en section 5.3.4).
La colonne index_lock_promotion_count de la fonction sys.dm_db_index_operational_stats est également utile.
MSSQL:Buffer Manager\Database pages: indique le nombre de pages de données cachées dans le buffer. Sur un système qui a suffisamment de RAM, cette valeur devrait peu évoluer. Si vous observez des changements importants de ce compteur, cela veut dire que SQL Server doit libérer des pages du buffer. Il manque certainement de la mémoire vive (il en manque physiquement, ou l’option max server memory limite son utilisation par SQL Server.
MSSQL:Buffer Manager\Free list stalls/sec: indique la fréquence à laquelle des demandes d’octroi de pages de buffer sont suspendues parce qu’il n’y a plus de pages libres dans le cache. Cette valeur doit être la plus petite possible. Une valeur dépassant 2 est un indicateur de manque de mémoire.
MSSQL:Buffer Manager\Page life expectancy: Indique le nombre de secondes pendant lesquelles une page de données va rester dans le buffer sans références, c’est-à-dire sans qu’un processus n’accède à cette page. Selon Microsoft, 300 secondes est la valeur minimum à obtenir, et l’idéal est la valeur la plus élevée possible. Si ce compteur indique 300, cela signifie qu’une page va être vidée du cache après 5 minutes à moins qu’elle soit utilisée dans ce laps de temps. SQL Server ajuste cette valeur selon la quantité de mémoire disponible pour le buffer. Moins il y a de mémoire, plus la durée de vie est courte, pour permettre à SQL Server de libérer de la place dans le buffer pour des données plus utiles. C’est donc un bon indicateur : si ce compteur tombe en dessous de 300, vous manquez manifestement de mémoire pour le buffer (ou vous avez malencontreusement limité l’option max server memory.
MSSQL:Buffer Manager\Page reads/sec et MSSQL:Buffer Manager\Page writes/sec: indiquent le nombre de pages lues depuis le disque et écrites sur le disque par le gestionnaire de cache de données. En corrélant ces valeurs avec vos informations provenant du disque, vous pouvez déterminer si l’activité disque est principalement générée par SQL Server. De même, plus ces valeurs sont élevées, moins votre cache travaille efficacement. En d’autres termes, plus vous manquez de mémoire vive.
MSSQL:Buffer Manager\Total pages: nombre total de pages de cache de données. Vous trouvez l’utilisation des pages dans d’autres compteurs du même groupe : dans database pages, les pages utilisées pour les données, dans free pages, les pages disponibles, dans stolen pages les pages libérées sous pression mémoire, pour d’autres utilisations, en général le cache de procédures. Target pages indique le nombre idéal de pages de buffer que SQL Server estime pour votre système. La différence entre Target pages et Total pages devrait évidemment être aussi mince que possible.
MSSQL:Databases\Log growths: nombre total d’augmentations de la taille physique des fichiers de journal de transaction pour une base de données. Cela vous indique si la taille du journal choisie à la base était bonne. L’augmentation automatique du journal diminue les performances d’écriture en fragmentant et en multipliant le nombre de VLF (Virtual Log Files).
MSSQL:Databases\Percent Log Used: pourcentage du journal en utilisation. Nous vous conseillons de créer une alerte de l’agent SQL testant cette valeur, pour vous notifier par exemple lorsqu’elle dépasse les 80 %, ou plus, selon votre système.
MSSQL:General Statistics\Active Temp Tables : nombre de tables temporaires utilisateur dans tempdb, à un moment donné.
MSSQL:General Statistics\Processes Blocked: ce compteur, nouveauté de SQL Server 2005, affiche le nombre de processus bloqués, c’est-à-dire de processus qui attendent, depuis un certain temps, la libération de verrous tenus par un autre processus, pour continuer leur travail. Lorsqu’un verrou est maintenu trop longtemps, il peut provoquer un « embouteillage » de verrous, les processus s’attendant les uns sur les autres. Vous pouvez utiliser ce compteur dans une alerte du moniteur système ou de l’agent SQL pour vous avertir de cette situation (une augmentation rapide et continue de ce compteur en étant le signe). Vous avez d’autres moyen de détection de cette situation, comme nous le verrons dans la section 7.5.1.
MSSQL:General Statistics\User Connections: nombre de sessions ouvertes. Une augmentation et une stabilisation de ce nombre peut indiquer des problèmes liés à un application qui ne gère pas bien les déconnexions.
MSSQL:Locks\Average Wait Time (ms): nombre moyen d’attentes pour la libération de verrous, en millisecondes.
Une valeur élevée indique une contention dûe à des transactions ou à des requêtes trop longues, qui verrouillent les données trop longtemps.
Le meilleur remède est de modifier le code, pour diminuer l’étendue des transactions et la durée des requêtes, ou leur niveau d’isolation.
Si cela n’est pas possible, il peut être utile de passer la base de données dans laquelle le verrouillage est important, en mode READ COMMITTED SNAPSHOT (voir section 7.3).
MSSQL:Locks\Number of Deadlocks/sec: nombre de verrous mortels par secondes. Si cette valeur est régulièrement en dessus de… 0, vous avez un réel problème. Reportez-vous à la section 7.5.2.
MSSQL:Plan cache\Cache Objects Count: nombre d’objets de cache par type de cache. L’instance SQL Plans indique le cache de plans d’exécution. Attention à la diminution violente de cette valeur : signe de pression sur la mémoire qui risque d’impacter fortement les performances.
MSSQL:SQL Errors\Erros/sec: signe d’erreurs, par exemple après modification de structure. Les erreurs sont à examiner à l’aide d’une trace SQL.
MSSQL:SQL Statistics\Batch requests/sec: nombre de requêtes SQL envoyées au serveur. Indique la demande de travail à laquelle votre serveur est soumis.
MSSQL:SQL Statistics\SQL Compilations/sec: nombre de compilation de plans par seconde. Une valeur élevée peut indiquer un manque de mémoire pour le cache de plans, ou un besoin de configurer l’auto-paramétrage plus agressivement (voir section 9.2).
MSSQL:SQL Statistics\SQL Re-Compilations/sec: nombre de recompilations par seconde. Une valeur élevée indique un problème de performance des requêtes. Identifiez les procédure incriminées à l’aide du profiler, et appliquez les solutions proposées dans la section 9.1.2.
Network Interface\Current Bandwidth et Network Interface\Bytes Total/sec : indique la capacité de votre connexion réseau, et son débit actuel, respectivement. La comparaison des deux vous donne l’utilisation actuelle (attention aux différences d’échelle dans l’affichage en graphe du moniteur de performance).
PhysicalDisk\Split IO/sec : requêtes d’entrées/sorties que Windows doit diviser pour honorer. Sur un disque simple, un nombre élevé est un indicateur de fragmentation. Attention, n’en tenez pas compte sur un système RAID, il est normal d’y trouver des splits.
Au sujet des compteurs de disque
L’objet PhysicalDisk fournit des compteurs par disque physique, et l’objet LogicalDisk par partition (lettre de lecteur).Les objets de compteurs de disque ont un effet sur les performances du serveur, même lorsqu’on ne les affiche pas avec le Moniteur Système. Pour cette raison, sur Windows NT ces compteurs sont totalement désactivés, et sur Windows 2000, seuls les compteurs physiques (PhysicalDisk) sont activés (donc l’objet LogicalDisk était désactivé). Un outil en ligne de commande, nommé diskperf, est à disposition pour activer ou désactiver ces compteurs. À partir de Windows Server 2003, ces compteurs sont activés par défaut, leur impact n’étant pas réellement significatifs sur les machines modernes.
diskperfest toujours présent si vous voulez désactiver une partie des compteurs. Sachez toutefois qu’une activation ou désactivation nécessite un redémarrage de la machine, ce qui rend son utilisation peu intéressante…
Process% Processor Time : ce compteur donne le temps CPU total utilisé par un processsus. C’est un cumul des compteurs % Privileged Time et % User Time du même objet.
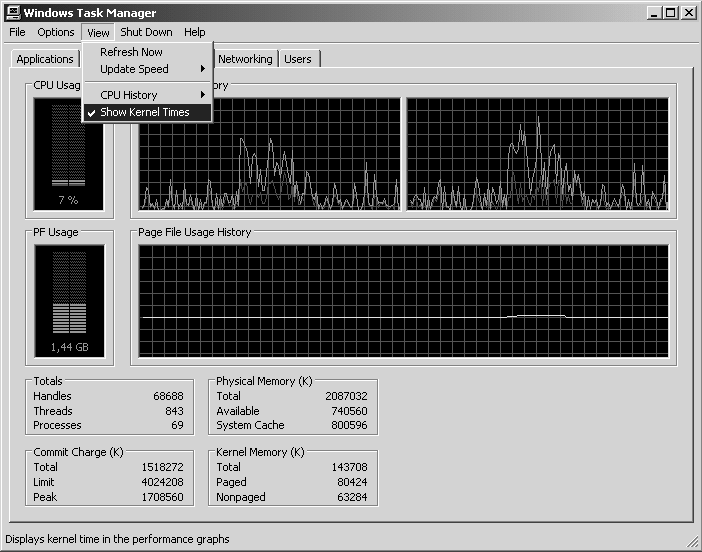
% Privileged Time est le pourcentage de temps CPU utilisé par le processus en mode privilégié. Le temps privilégié (privileged time, ou kernel time), est le temps d’activité des CPU dédiés aux appels système (gestion de la mémoire, entrées/sorties, etc.). C’est souvent le cas d’un service Windows qui a besoin d’accéder aux données privées du système, qui sont protégées contre des accès de processus s’exécutant en mode utilisateur. Les appels implicites au noyau, comme les fautes de page, sont aussi comptées comme du temps privilégié. Sur une machine dédiée à SQL Server, le pourcentage de temps privilégié devrait être faible, SQL Server exécutant la majeure partie de son travail en temps utilisateur. Vous pouvez obtenir une vision rapide du ratio temps privilégié / temps utilisateur à l’aide du gestionnaire de tâches (Windows task manager). L’onglet performance montre notamment des graphes de CPU. Vous pouvez afficher la partie de temps privilégié (appelée ici kernel time), en activant dans le menu view l’option show kernel times, que vous voyez en figure 5.14.
System\Context Switches/sec : Indique le nombre de changements de contexte à la seconde. Dans un environnement multiprocesseurs, un nombre de threads plus important que le nombre de processeurs, s’exécute en multitâche préemptif[^15]. Le système d’exploitation est responsable d’attribuer des temps d’utilisation processeur pour chaque thread. Il organise donc une répartition d’exécution, comme un animateur de débat télévisé qui distribue les temps de parole tout au long de l’émission. Chaque thread s’exécute dans un contexte, son état est maintenu, notamment dans les registres du processeurs. Passer d’un thread à l’autre implique donc de remplacer le contexte du thread remis dans la pile, par le contexte du thread à qui l’OS redonne le processeur.
Nous avons vu que SQL Server implémente une couche appelée SQLOS, qui est un environnement semblable à un système d’exploitation en miniature. Cet environnement gère ses propres threads, appelés « worker threads », mappés par défaut à des threads Windows. Un réservoir (pool) de worker threads est maintenu par SQLOS pour exécuter les tâches du serveur SQL. Le nombre de threads dans ce pool est déterminé par l’option de configuration du serveur « max worker threads ».
La valeur par défaut de cette option est 0, qui correspond à une auto-configuration de SQL Server. Cette valeur est optimale dans la grande majorité des cas. Si vous avez effectué une mise à jour directe d’une instance SQL Server 2000 vers 2005, vérifiez que cette valeur est bien à 0. En effet, en SQL Server 2000, la valeur par défaut était 255, et elle demeure lors de la mise à jour. L’autoconfiguration en SQL Server 2005 suit une logique relative au nombre de processeurs, expliquée dans les BOL sous l’entrée « max worker threads Option ».
Pour connaître la valeur actuelle sur votre système :
SELECT max_workers_count
FROM sys.dm_os_sys_info
Il est hasardeux d’augmenter le nombre de worker threads, et en général inutile, voire contre-performant[^16]. Cette option n’est pas un option intéressante pour augmenter les performances.
Donc, les changements de contexte sont coûteux, mais nécessaires. Des valeurs comme 10 000 ou 15 000 sont normales. Une augmentation exagérée de context switches devient un problème, car les processeurs passent trop de leur temps à changer de contexte. Dans ce cas, une augmentation du nombre de processeurs est à envisager.
Dans un système en architecture SMP qui comporte beaucoup de processeurs, où le nombre de changements de contexte est élevé de façon consistante, et où les processeurs sont en utilisation presque maximum en permanence, vous pouvez essayer de configurer SQL Server pour l’utilisation de fibres. Les fibres sont des threads plus légers, qui peuvent changer de contexte sans quitter le mode utilisateur. Après activation de ce mode, SQLOS mappe ses worker threads à des fibres et non plus à des threads Windows. Passer du mode thread au mode fibre se fait en changeant l’option de serveur lightweight pooling, comme ceci :
EXEC sp_configure 'show advanced options', 1
RECONFIGURE
EXEC sp_configure 'lightweight pooling', 1
RECONFIGURE
EXEC sp_configure 'show advanced options', 0
RECONFIGURE
Ce changement n’est pas à faire à la légère, car il peut aussi avoir un effet négatif. En tout cas, le gain a peu de chances d’être spectaculaire. Notez également que SQL Mail n’est pas disponible en mode fibre (ce qui a peu d’impact, car vous l’avez certainement remplacé par l’outil Database Mail), ni le support des objets de code .NET.
Un compteur Thread\Context Switches/sec vous permet aussi d’entrer dans les détails : quels threads sont beaucoup déplacés.
System\Processor Queue Length : indique le nombre de threads qui sont dans la file d’attente du processeur. Ce sont donc des threads qui attendent que le système d’exploitation leur donne accès à un processeur. Il y a une seule file d’attente, quel que soit le nombre de processeurs. En divisant ce nombre par la quantité de processeurs, vous avez une idée du nombre de threads en attente sur chacun. En-dessus de 10 threads en attente par processeur, commencez à vous inquiéter.
Compteurs pour tempdb
MSSQL:Access Methods\Worktables Created/sec : nombre de tables de travail créées par seconde. Les tables de travail sont utilisées par le moteur d’exécution de SQL Server pour résoudre des plans de requête contenant du spooling.
Ce nombre devrait rester inférieur à 200.
Les moyens d’éviter les tables de travail sont d’améliorer la syntaxe des requêtes (et d’éviter les requêtes sans clause WHERE, qui doivent traiter trop de lignes), de diminuer l’utilisation des curseurs ou des objets larges (LOB), et de créer les index nécessaires aux tris préliminaires dans les requêtes.
MSSQL:Access Methods\Workfiles Created/sec : nombre de fichiers de travail créées par seconde. Les fichiers de travail sont utilisés par le moteur d’exécution dans des plans de requête utilisant le hachage. Pour diminuer les fichiers de travail, évitez le traitement de jeux de résultats trop importants : le hachage est utilisé dans les jointures et les regroupements qui doivent traiter un nombre important de tuples.
MSSQL:General Statistics\Temp Tables Creation Rate : le nombre de tables temporaires et variables de type tables créées par seconde. Utile pour différencier, dans une utilisation importante de tempdb, ce qui revient à la création de tables temporaires utilisateurs par rapport aux version stores et aux fichiers et tables de travail.
MSSQL:Transactions\Free Space in tempdb (KB) : utile pour détecter un manque d’espace libre dans tempdb. Une bonne idée est de créer une alerte de l’agent SQL sur un dépassement de cette valeur.
MSSQL:Transactions\Version Store Size (KB) : indique la taille des version stores pour les versions de ligne (row versioning). Cette valeur devrait évoluer dynamiquement au fur et à mesure de l’utilisation du row versioning, et donc diminuer quand les besoins de versions diminuent. Une taille de version store qui continue d’augmenter indique un problème, probablement une transaction ouverte trop longtemps, qui empêche les versions de ligne d’être libérées.
MSSQL:Transactions\Version Generation Rate (KB/s) et MSSQL:Transactions\Version Cleanup Rate (KB/s) : indiquent le nombre de Ko de version stores créés et supprimés par seconde. Des valeurs importantes indiquent une utilisation importante du row versioning, mais si les compteurs généraux du système (disque, mémoire, CPU) ne montrent pas de pression excessive, c’est le signe d’un fonctionnement de tempdb non bloquant, ce dont on peut se féliciter. En revanche, la corrélation avec une augmentation de la pression sur le système, peut nous donner des indications de sa cause.
Compteurs utilisateur
L’objet de compteurs MSSQL:User Settable permet de récupérer des compteurs générés explicitement dans votre code. Utilisez-le pour afficher des statistiques sur des opérations dont vous voulez connaître la fréquence d’utilisation, ou le volume. Vous pouvez par exemple renvoyer un nombre de lignes affectées par un traitement, ou le nombre de lignes dans une table.
Vous disposez de dix compteurs, numérotés de 1 à 10. Vous devez mettre à jour la valeur du compteur, en exécutant la procédure stockée sp_user_counterX, ou X est le numéro du compteur.
Par exemple, pour passer le nombre de lignes affectées par la dernière instruction de votre procédure au compteur 1, vous écririez :
EXEC sp_user_counter1 @@ROWCOUNT
Cette valeur sera attribuée au compteur, qui la restituera tant que vous n’exécuterez pas sp_user_counter1 à nouveau. Ainsi, pour afficher le nombre de lignes d’une table (sa cardinalité), vous pouvez créer un déclencheur sur INSERT et DELETE, qui exécute cette procédure.
Retrouver la session coupable
Lorsque vous constatez une augmentation anormale de l’activité CPU, vous souhaitez sans doute entrer dans les détails et identifier la session SQL Server responsable.
C’est possible en corrélant l’identifiant de thread Windows et le kpid des informations de session SQL Server. Le désavantage de cette opération est son côté fastidieux, et surtout sa durée : il se peut qu’une fois la première partie de l’opération effectuée, la session ait déjà terminé son travail, et donc qu’on arrive trop tard pour recueillir les informations nécessaires.
Vous devez premièrement trouver l’identifiant du thread qui consomme un niveau important de CPU. Vous disposez pour cela des compteurs de performances Thread : % Processor Time et Thread : ID Thread.
Sélectionnez toutes les instances Sqlservr. Affichez le résultat en mode rapport et cherchez le thread consommateur, comme indiqué en figure 5.15.
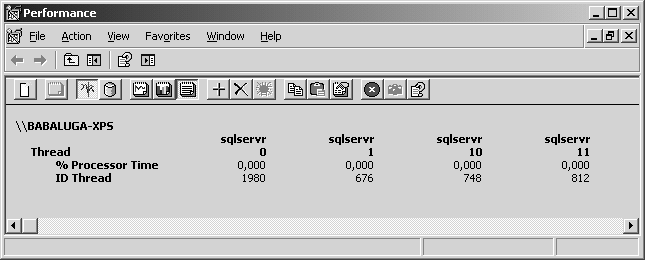
Lorsque le thread est identifié, vous trouvez la correspondance dans SQL Server à partir de la colonne kpid de la vue sys.sysprocesses (une vue qui correspond à l’ancienne table système du même nom), qui représente le même identifiant :
SELECT *
FROM sys.sysprocesses
WHERE kpid = *ID_Thread*;
Utiliser les compteurs dans le code SQL
La vue système sys.dm_os_performance_counters permet de retrouver dans du code SQL des valeurs de compteurs de performance.
Elle remplace la table master.dbo.sysperfinfo de SQL Server 2000.
Cette table est toujours disponible, mais elle est dépréciée, il est donc recommandé d’utiliser la vue de gestion dynamique pour la remplacer.
Cette vue ne permet de retrouver que les compteurs propres aux objets SQL Server, et pas les compteurs des objets système.
Vous pouvez ainsi, dans votre code, requêter ou réagir aux valeurs de compteur. Voici par exemple une requête qui vous indique quel est le pourcentage du journal de transaction rempli, pour chaque base de données :
SELECT
instance_name,
cntr_value as LogFileUsedSize
FROM sys.dm_os_performance_counters
WHERE counter_name = 'Log File(s) Used Size (KB)';
Programmer des journaux de compteurs
Le moniteur de performances ne permet pas seulement de suivre en temps réel l’activité du serveur, il est aussi capable d’enregistrer cette activité dans des fichiers, afin de conserver une trace rechargeable ensuite dans le même outil, pour obtenir une vue sur une longue période.
C’est bien sûr l’outil de base pour établir la baseline dont nous avons déjà parlé. Pour ouvrir un fichier de journal de compteur, lancez le moniteur système et, au lieu de suivre les compteurs en temps réel, choisissez de lire les données d’un fichier. Vous avez un bouton sur la barre d’outil, en forme de cylindre, qui vous permet de charger le fichier. Combinaisons de touches : CTRL+T pour voir l’activité du serveur en temps réel, CTRL+L pour ouvrir un fichier de journal.
Pour créer un journal de compteurs, un dossier nommé performance logs and alerts, comportant une entrée nommée counter logs est visible dans l’arborescence de la console, comme affiché dans la figure 5.16.

Trace logs : vous voyez sur la figure 5.16 une entrée Trace logs, qui correspond aux traces générées par l’architecture ETW (Event Tracing for Windows). Cette partie est utile en SQL Server 2008 pour gérer des sessions d’événements étendus. Voir plus loin section 5.3.5.
Par un clic droit sur l’entrée « counter logs », ou dans la fenêtre de droite, vous pouvez créer un nouveau journal en sélectionnant new log settings… dans le menu. La première étape est de donner un nom à votre définition de journal, puis de sélectionner les compteurs désirés, en cliquant sur le bouton Add counters…, dans la fenêtre reproduite en figure 5.17.
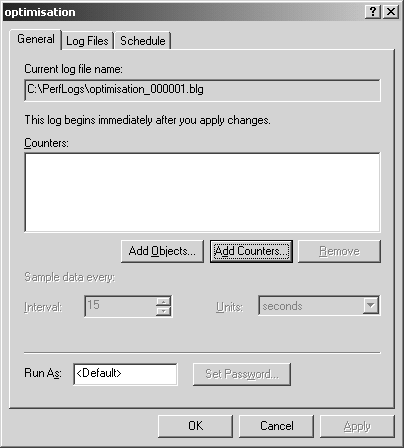
Vous ajoutez ensuite vos compteurs comme dans le moniteur système. Choisissez dans cette même fenêtre l’intervalle d’échantillonnage (sample data every…). Un échantillonnage trop fin augmente exagérément la taille des fichiers de journal, et impacte les performances du serveur.
Inversement, un intervalle trop important risque de ne pas montrer assez précisément les variations de compteurs et les pics brusques d’activité. Essayez avec l’intervalle qui vous convient. De dix à quinze secondes peut être une bonne valeur de départ.
La fenêtre de configuration de la définition du journal a trois onglets. Le deuxième permet de configurer la destination (figure 5.18).
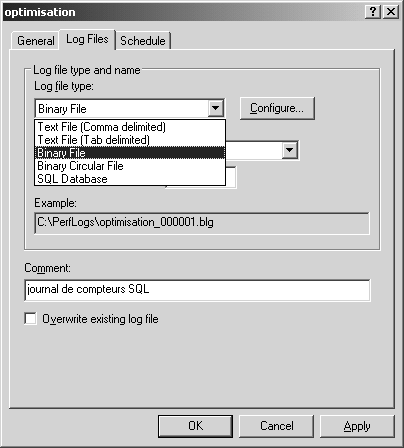
Vous pouvez enregistrer les informations de compteurs dans un ou plusieurs fichiers texte ou binaire, ou dans une table SQL.
Comme pour le profiler, évitez d’enregistrer directement dans une base de données, pour d’évidentes raisons de performances. Le fichier binaire sera le plus rapide et le plus compact. Choisissez un fichier texte si vous souhaitez importer ensuite votre journal dans une table SQL pour l’inspecter par requêtes, ou si vous importez les résultats dans un outil de supervision ou un générateur de graphes. Vous pouvez limiter la taille du fichier, ou programmer une rotation.
Outils en ligne de commande : les journaux de performance et les sessions d’événements ETW peuvent être gérés en ligne de commande, grâce à l’exécutable logman.exe. Vous pouvez créer, lancer et arrêter des traces. Par exemple, pour démarrer et arrêter un journal de compteur nommé sqlcounters créé dans l’interface :
logman start sqlcounters logman stop sqlcounters
Les fichiers générés par le journal peuvent être facilement convertis entre des formats texte, binaire, et une table SQL, à l’aide de l’exécutable relog.exe, livré avec Windows.
Programmer des alertes
Le moniteur système vous permet également de programmer des alertes, un peu dans l’esprit de l’agent SQL. Vous pouvez utiliser indistinctement l’un ou l’autre outil pour programmer un envoi de notification lorsqu’un compteur atteint un certain seuil, mais aussi – ce qui peut se révéler très pratique – pour déclencher une collecte d’information spécifique.
Imaginez que vous vouliez démarrer une trace SQL et un journal de compteurs aussitôt que l’activité des processeurs atteint 90 %, afin d’obtenir les données au bon moment, c’est-à-dire quand la montée en charge se produit.
Vous pourriez programmer une alerte dans l’agent SQL, mais vous pouvez aussi le faire dans le moniteur système. Les actions déclenchées seront les mêmes, voyons-le avec le moniteur système.
Dans le dossier Performance logs and alerts du moniteur système, faites un clic droit sur le sous-dossier Alerts, et choisissez New Alerts Settings…. Après avoir choisi un nom parlant, sélectionnez un compteur de performance avec le bouton Add. Pour cet exemple, nous prendrons Processor(_Total)% Processor Time.
Le deuxième onglet, Action, vous permet de réagir à l’alerte. Nous allons utiliser la possibilité de démarrer un journal de compteurs, et de lancer une commande du système. Ainsi, nous pouvons lancer, dès que le besoin s’en fait sentir, un journal de compteurs.
Vous pouvez aussi, comme nous l’avons vu, planifier le journal de compteurs pour s’arrêter après une certaine durée, ce qui vous permettrait par exemple de conserver dans des fichiers numérotés séquentiellement, des traces de trente minutes, dès que la charge des processeurs atteint 90 %.
En utilisant l’exécution d’une commande, vous pouvez en même temps démarrer une trace.
Le plus simple serait, à l’aide d’une commande SQLCMD, de lancer une trace stockée sur le serveur.
Nous avons vu la procédure sp_trace_setstatus dans la section 5.2.2.
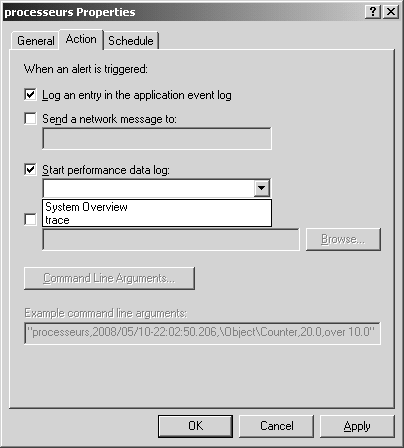
Dans le dernier onglet, montré en figure 5.19, vous indiquez les plages de temps pendant lesquels l’alerte sera active, c’est-à-dire durant quelle période elle peut se déclencher.
Corréler les compteurs de performance et les traces
Nous avons vu que vous pouvez enregistrer aussi bien les traces SQL que les journaux de compteur. Si vous collectez les deux jeux d’informations, vous pouvez utiliser l’interface du profiler pour corréler les informations dans un affichage regroupé, très utile pour identifier les causes de surcharge.
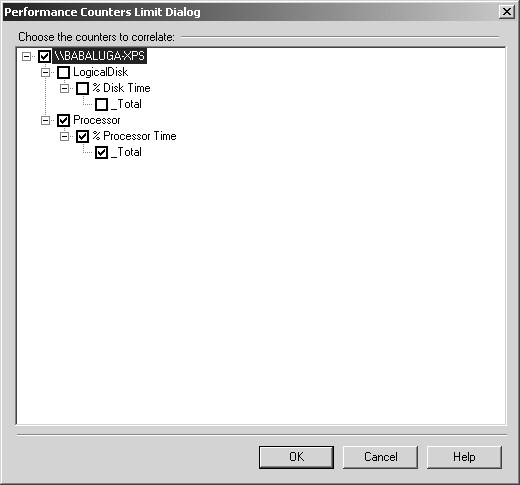
Lorsque vous avez vos fichiers enregistrés : le journal de compteurs et le fichier de trace, ouvrez d’abord ce dernier dans le profiler. Vous verrez, ensuite, dans le menu Fichier, la commande Importer les données de performance. Sélectionnez le fichier de journal de compteur, choisissez les compteurs enregistrés que vous voulez voir apparaître (figure 5.20).
Vous verrez ensuite dans le profiler les deux fenêtre l’une sous l’autre : les événements de trace, puis les graphes de performance (figure 5.21).
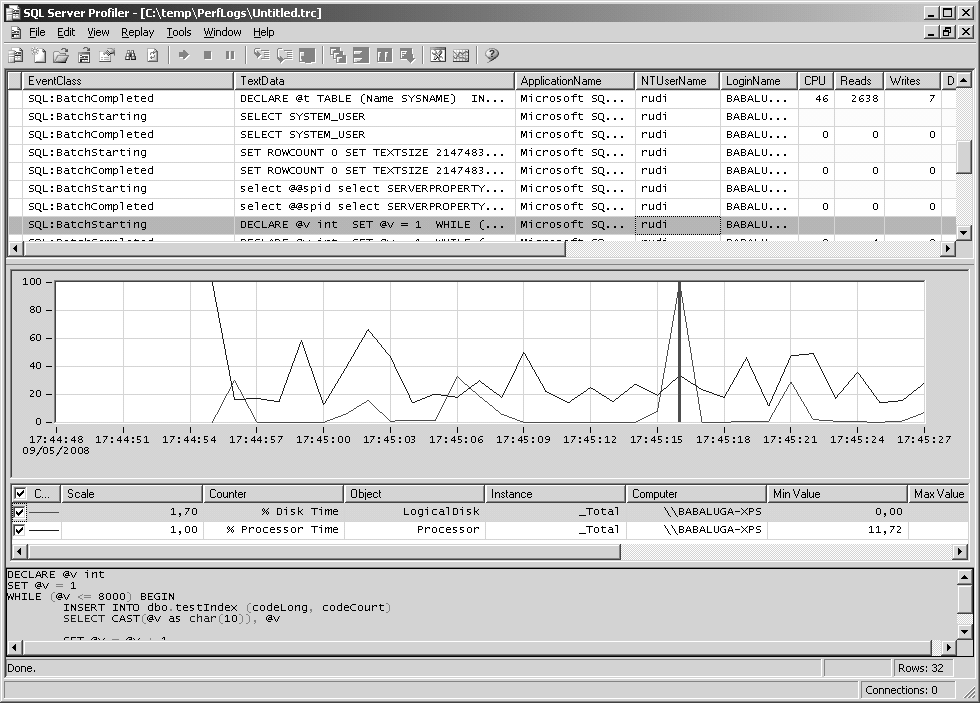
Vous pouvez ensuite vous situer sur une ligne d’événement, ou à un moment du graphe, et l’affichage de l’autre fenêtre sera automatiquement positionné sur la période correspondante. Cela vous permettra une analyse détaillée de l’impact de vos requêtes sur le serveur. Cette fonctionnalité n’est possible qu’avec des traces et des journaux de compteurs sauvegardés préalablement, la corrélation en temps réel n’est pas possible.